前几日,下了班在家时突然收到监控报警,线上一组业务机器 CPU 被打满至 100%,为了保持服务的稳定运行,临时采取了升级配置、加机器等粗暴的方法将当晚扛了过去。
半夜想了下可能的原因,由于可能因素太多,不能确定,第二天到公司后,在一台预发机器上把 Java Mission Control 所需的参数配置好,然后就等待下一次问题出现呗,果然,没几天,在晚高峰时问题又复现了,马上将线上的流量分了一小部分到提前配置好的预发机器上,没过一会,预发机器的 负载 也满了。在 Java Mission Control 的 Thread 的面板里观察了一会,业务线程的 CPU 使用率根本不高,超过 10% 的都很少,但此时 CPU 又是被打满的,在不停查看 Java Mission Control 中提供的信息时,发现了 Full GC 非常频繁,在应用启动了两个多小时内,Full GC 了 1500 多次,占用了 13 多分钟,并且次数和时间依然在不停增加中,一下让我想到了之前在相关书籍上提到的频繁 Full GC 的相关问题,没想到在这里让我给碰上了,如图:
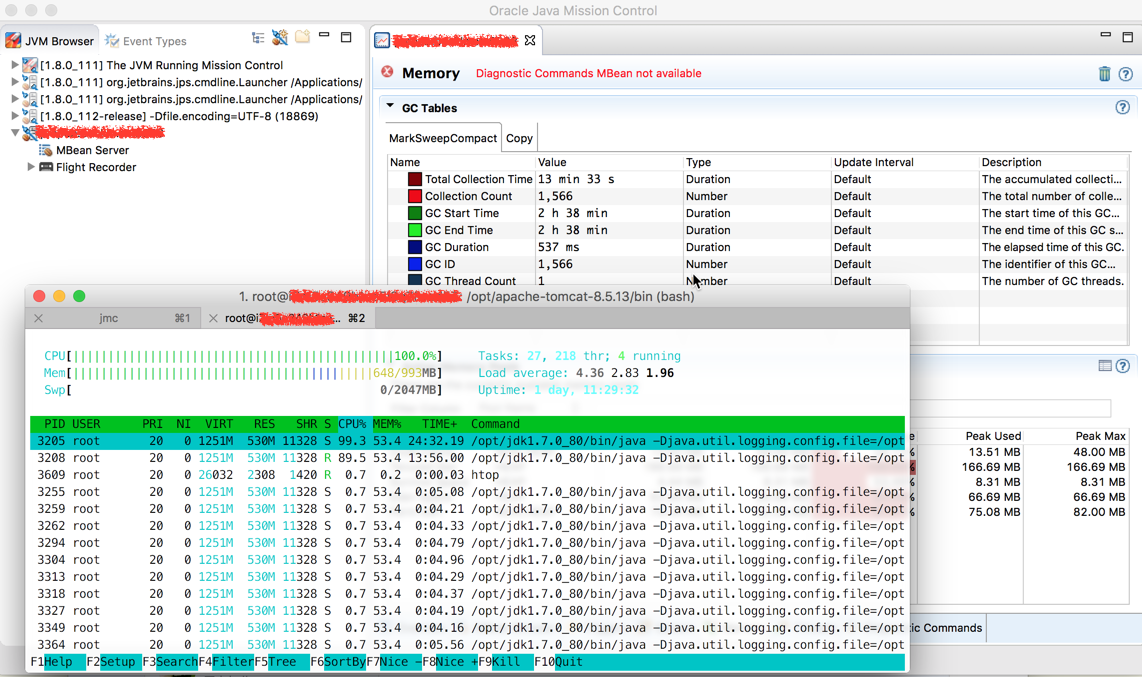
但是预发机器和线上机器配置是不一样的啊,预发是 Full GC 导致的 CPU 飙升不能代表线上机器也是这个原因啊,为了验证此问题,我在其中一台线上机器配置了 GC log 等参数,就等着线上问题再出现时能留下相关日志信息,GC log 相关知识可参考: Understanding the Java Garbage Collection Log 。是否感觉肉眼分析 GC log 很麻烦?好吧,早就有人做好了相关分析工具: GC easy 。
这里提供一份 GC log,是在一台线上 1Core 4G 的机器上采集的 (JVM 未调优),也是到了晚高峰 CPU 就 100% 了,可以自行上传到 GC easy 分析看看,点此 下载。
一图胜千言: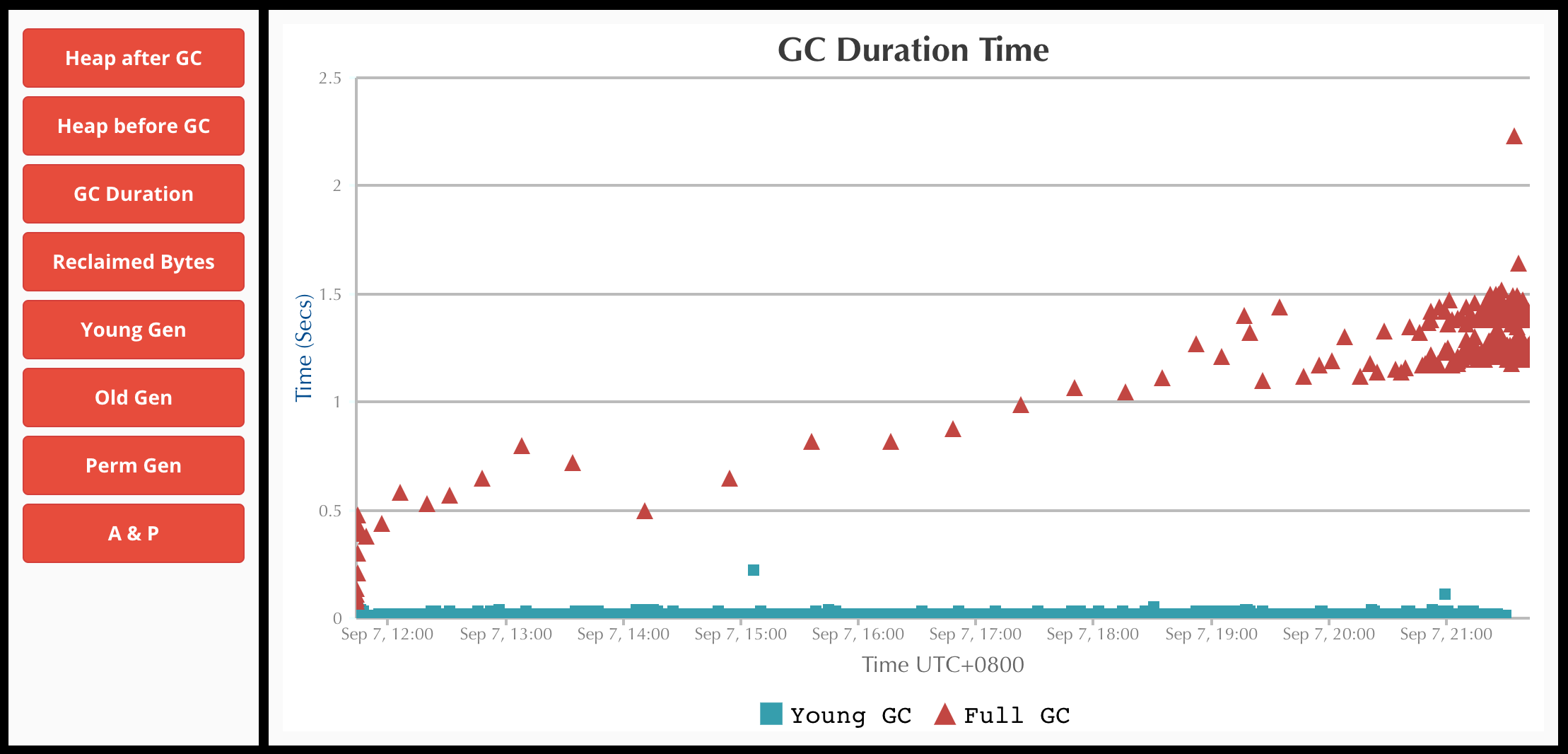
为了检查是否有部分业务线程存在大幅使用 CPU 的情况,我也顺便准备了 生成线程转储 相关命令,如:先用 jps 找出 tomcat 的 pid,然后使用如下命令生成线程转储:
1 | jstack -l <pid> > /opt/threadDump.txt |
为了保证数据的准确性,在 CPU 被打满的时间段内我生成了五六份以备后面分析,同样,用肉眼观察总是比较艰难,此处可利用 Java Thread Dump Analyzer 进行分析。这一块在线上机器上的分析和我之前在预发机器上观察的现象一致,没有存在大量消耗 CPU 的问题线程。
到此为止,问题总算找到了,只要找到原因所在,解决总是比较简单的,之前由于这组业务量不大,就没有进行 JVM 调优,使用的默认的 JVM 相关参数,比如在 1Core 4G 的机器上,默认 最大堆内存 为物理的内存的四分之一,还有很多内存没有得到利用,后面的解决办法也不用写了,调整后观察了一周,到目前为止晚高峰时服务依然很稳定,负载也在预期的范围内,没有再出现 CPU 飙升的情况,问题得到解决。