在我们的每日离线数据同步任务中,需要将在线业务数据同步至离线 Hive 数仓,而离线数仓存储使用的阿里云 OSS,Spark 与 OSS 数据交互使用的连接器为 EMR-OSS。我们发现,有极低的概率会出现 SQL 执行卡住,大约几个月会出现一次,且因为问题都发生在凌晨,所以每次收到数据同步延迟告警时我都临时将对应 SQL 进行了 kill,然后手动对出错的表数据进行了校准并重新同步,然后白天使用相同的 SQL 尝试复现该问题时,一直未能复现该问题,我当时还写了个 for 循环生成不同大小的文件然后使用该连接器读取以尝试复现该异常,但是实在是太慢了,使用多线程跑了几天都没跑出一个能触发该异常的文件,而在上周的一个凌晨,问题又出现了,这一次,我保留了现场。
我将线上出现异常涉及到的数据复制到测试环境后,在测试环境稳定复现了该异常,在测试环境复现的截图如下:
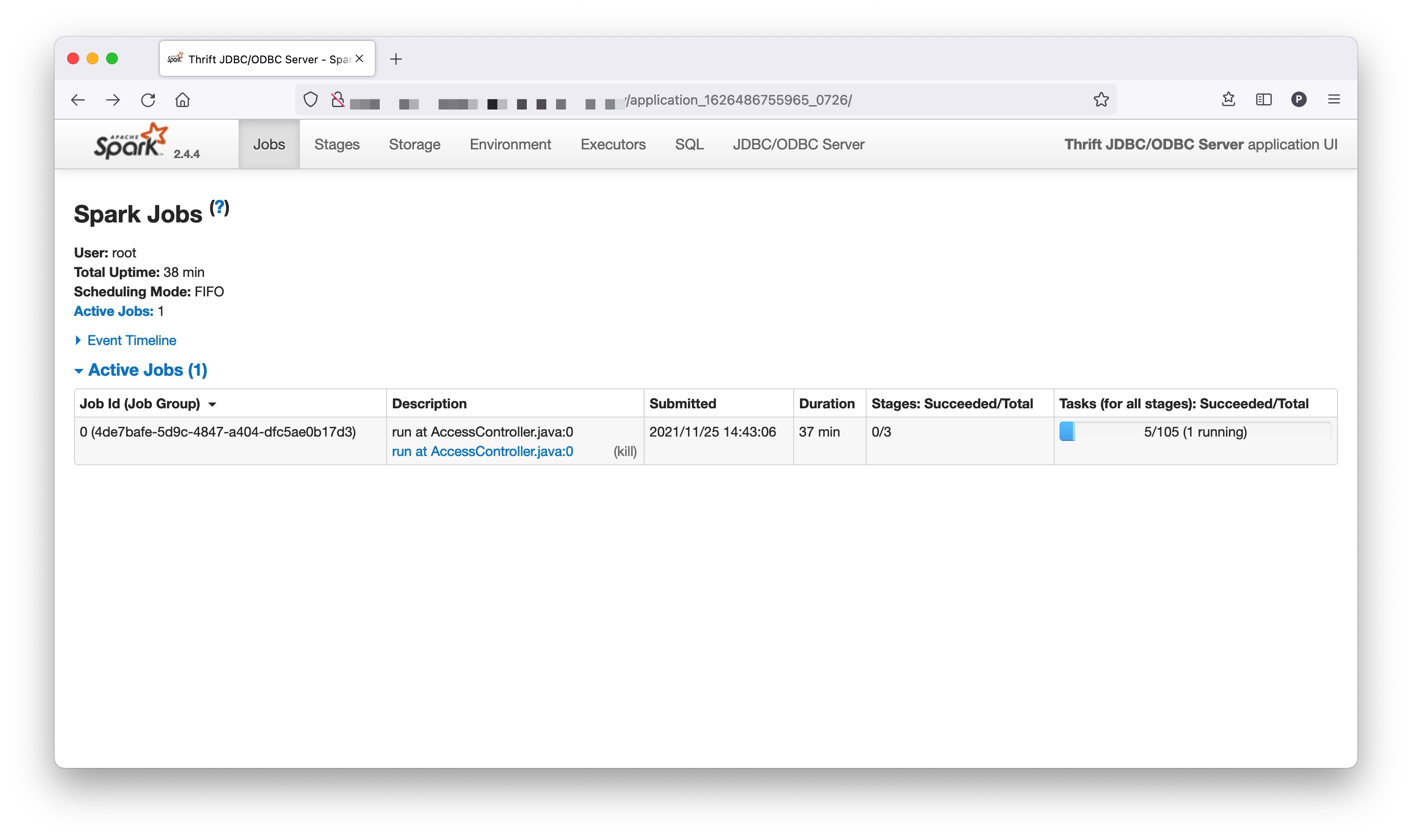
表现即为 SQL 执行卡住,如果查看对应 Executor 的 err 日志,可以发现如下异常: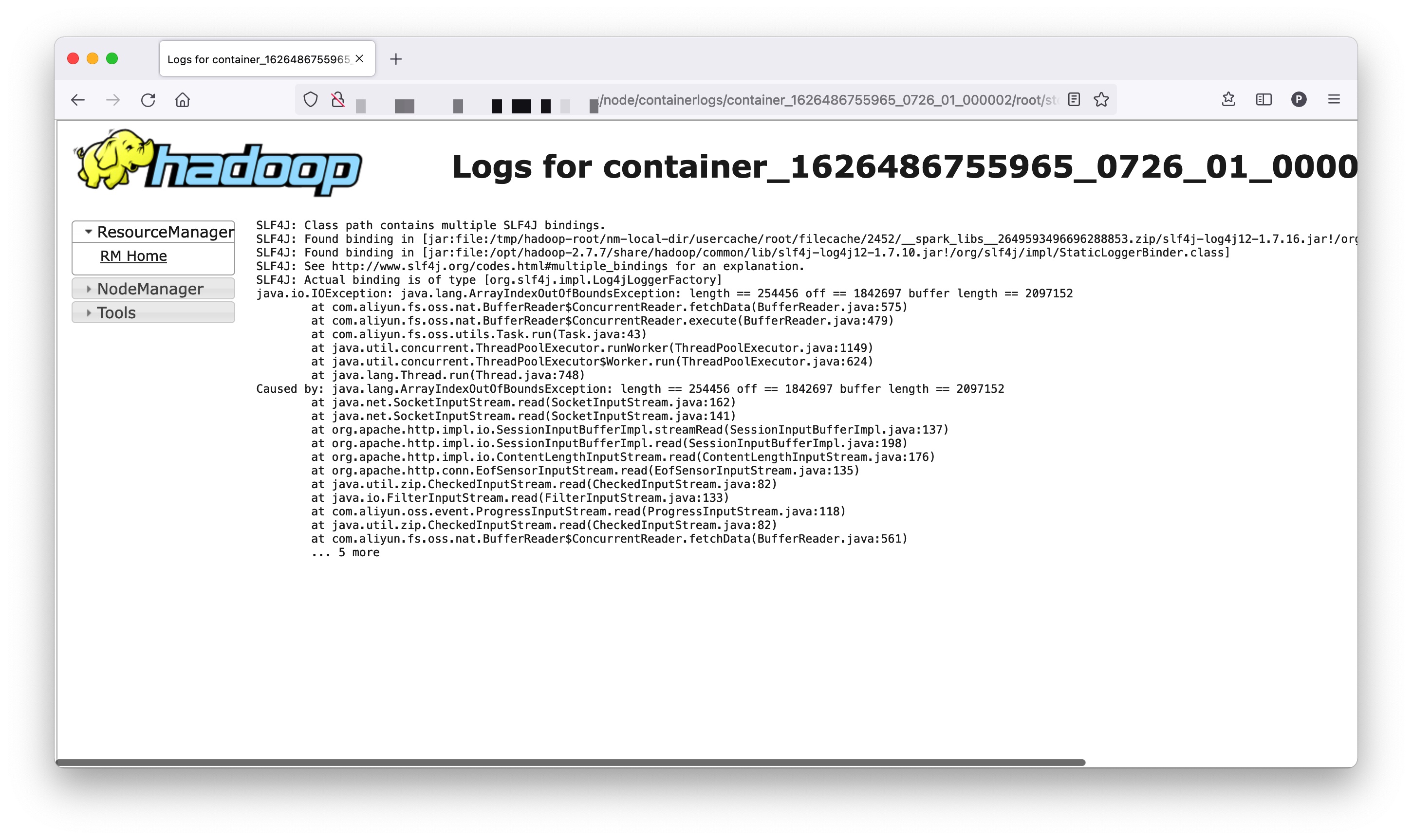
可以看出,出现了 ArrayIndexOutOfBoundsException,根据截图中异常可知,off = 1842697,length = 254456,buffer length = 2097152。我们将 off 与 length 相加可以得到 off + length = 1842697 + 254456 = 2097153,刚好比 buffer length 多出一个字节,令我不解的是,即使出现了数组越界异常,SQL 也应该抛出异常,而不应该卡住。于是,我查看了该 Executor 的线程转储:
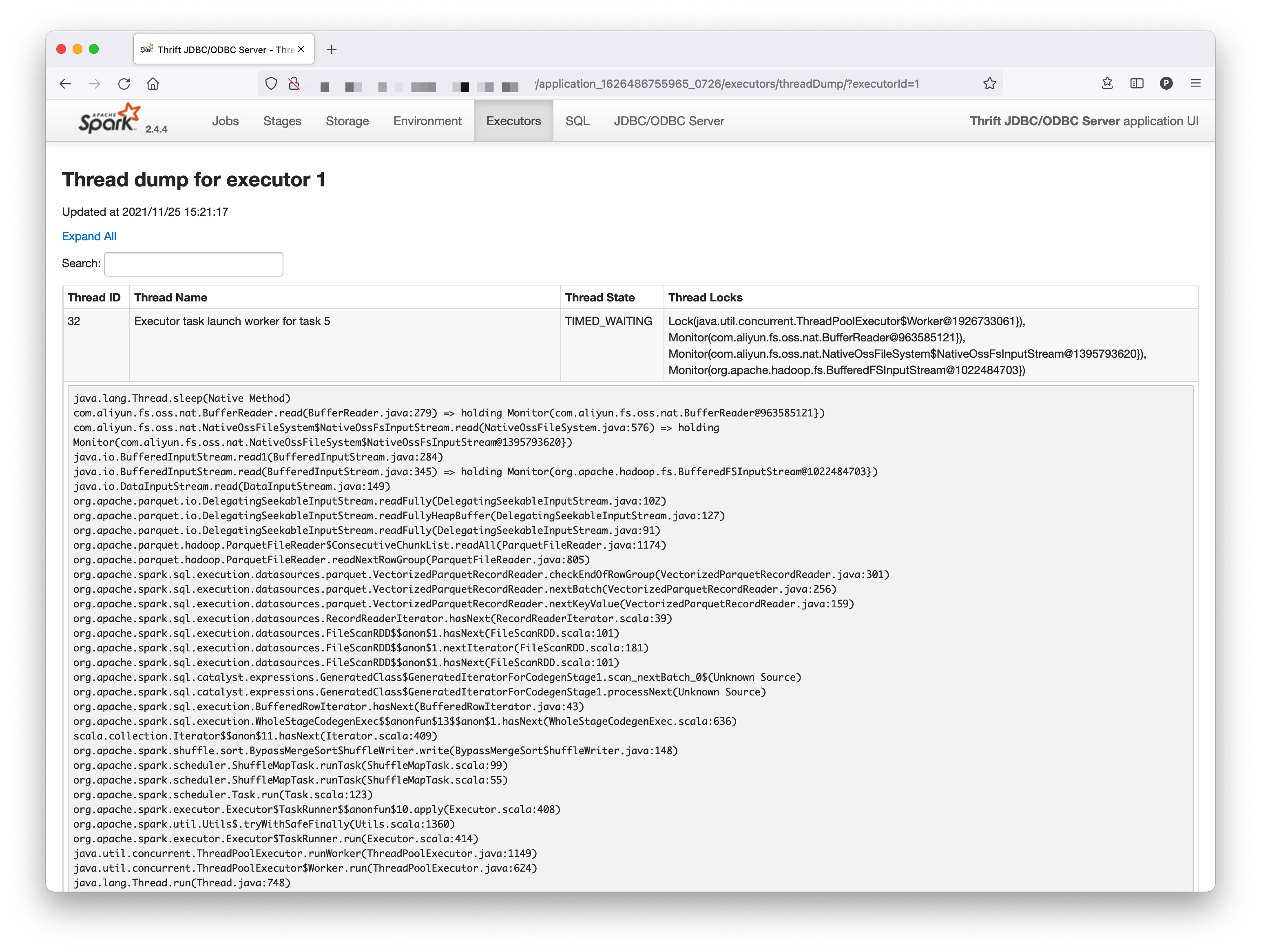
根据线程转储,我们知道负责 SQL 执行的线程当前正在 sleep,就是因为它的 sleep 导致我不能 sleep…
Executor 的 err 日志及线程转储都共同指向了一个类,即 com.aliyun.fs.oss.nat.BufferReader,我们线上环境使用的 EMR-OSS 连接器的版本为 1.8,该类的源码位于 BufferReader.java,感兴趣的可以先看一看。
到这里,问题已经定位到与 BufferReader 类有关,所以我尝试在本地复现该问题,因为本地能够更好调试验证该问题,了解 Spark 的同学应该都知道一个目录下通常有许多文件,此时,我想找出是哪一个文件导致 BufferReader 异常及 sleep,于是我对该 Executor 发起了一次堆转储,在堆转储中,找到该线程,根据当前正在 sleep 的 BufferReader 实例中的 key 属性定位到了该文件。
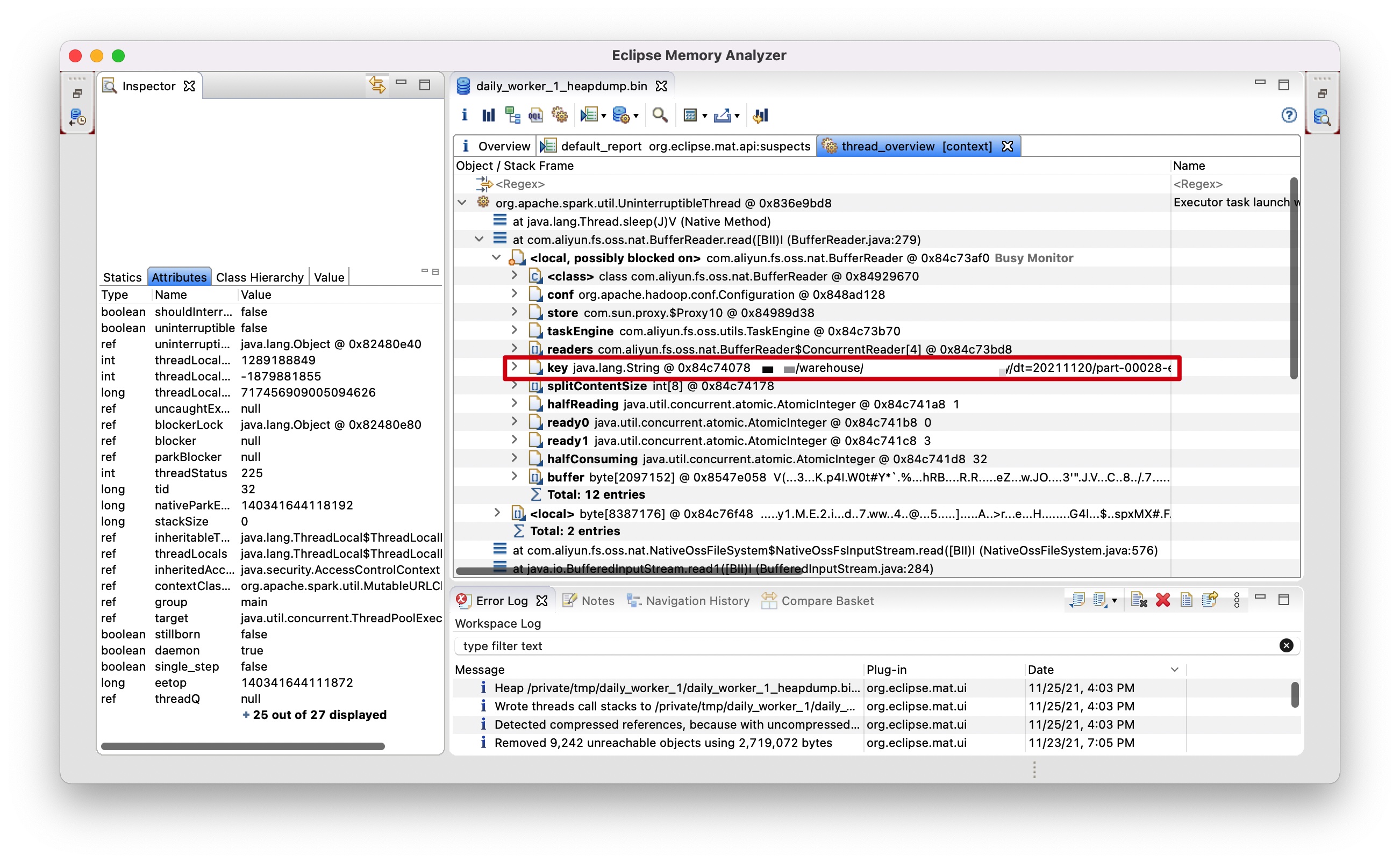
该文件的文件名为 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000,然后我将卡住的 SQL kill 掉,并重新执行该 SQL 数次,发现每次 SQL 执行都会卡住,然后堆转储中 sleep 的 BufferReader 实例中的 key 均为 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000,让我更加怀疑该文件,是什么原因导致 BufferReader 出现数组索引越界并处于 sleep 调用中。
于是,我尝试在本地使用 EMR-OSS 连接器读取文件 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000 来复现该问题。根据上文的截图我们知道,sleep 的调用栈帧中对 EMR-OSS 的调用入口为 com.aliyun.fs.oss.nat.NativeOssFileSystem.NativeOssFsInputStream.read(),我在本地使用 TestAliyunOSSInputStream.java 中的单元测试,将代码适当调整后读取文件 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000 尝试在本地复现该问题,很遗憾,读取文件没有出现异常,也没有出现 sleep。根据之前 sleep 截图的栈帧我们知道,停留在 NativeOssFileSystem.java 的 576 行的 read 方法调用上,该行的代码位于 NativeOssFileSystem.java:576,源码为 return bufferReader.read(b, off, len),可知调用的 bufferReader 带参数的 read 方法。这让我怀疑是否需要特定参数值的 read 方法调用才能触发该异常,于是我尝试从堆转储中拿到 sleep 栈帧中的 read 方法的调用值,我在 MAT 中并没有找到栈帧的方法参数值,然后查询相关文档,好像堆转储中是不包含线程调用时的方法参数值的(如有不对请指正),比如如下链接:Eclipse Community Forums: Memory Analyzer (MAT) » How to get executing stack and local variable information?。为了验证我的想法,我使用 Arthas 对 BufferReader 对文件 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000 的相关方法调用进行了跟踪,拿到了调用记录,其最后一次打开文件到 sleep 的调用链路如下:
1 | new BufferReader(store, 'part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000', conf, 1); |
上面的调用链路看起来很有规律的样子,在单元测试中,我使用如上的调用链路成功复现了异常,输出日志如下:
1 | 2021-11-27 21:36:36,587 INFO nat.NativeOssFileSystem (NativeOssFileSystem.java:open(435)) - Opening '/tmp/part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000' for reading |
从日志可以看出,异步读取的线程发生了数组索引越界异常,而 BufferReader 一直在等待异步线程将数据读取完毕,很明显,BufferReader 永远等不到这一刻了…
其中日志中的这一行引起了我的注意:
1 | 2021-11-27 21:36:37,217 INFO nat.BufferReader (BufferReader.java:updateInnerStream(359)) - Opening key 'part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000' for reading at position '4'. |
即从 position: 4 开始读取,与代码里的 bufferReader.seek(4) 相匹配,而之前我测试没有复现出异常问题的读取代码中是没有 seek() 方法调用的,这使我开始怀疑这个方法与异常存在着某种联系,于是我注释掉了 bufferReader.seek(4) 这一行再次运行单元测试,果然,没有异常出现。那么为什么 seek(4) 调用后就会触发数组下标异常呢?读取文件为何要调用 seek(4) 呢?于是我再次查看了之前 sleep 时的线程转储,发现该文件读取操作是由 parquet 包下的相关类发起,于是查询了该文件所属的 Hive 表,发现果然是 parquet 格式的,根据 Apache Parquet 中的描述我们可以知道,parquet 的文件格式如下:
1 | 4-byte magic number "PAR1" |
即前 4 个字节为魔数,然后就是各个列各个块的数据,这与我们捕捉到的读取调用链相符合,然后我又查看了文件 part-00028-e2cd9234-e0f8-488b-8ae7-1853e227bb01-c000 的大小,为 33554434 字节,即比 32MiB 多两个字节,如果我们不调用 seek() 方法直接读取整个文件,则会读取 33554434 个字节,而如果我们调用 seek(4) 方法跳过前 4 个字节后再读取该文件,则会读取 33554434 - 4 = 33554430 个字节,即比 32MiB 少两个字节。为了验证我的想法,我生成了一个大小为 33554430 的文件,然后直接使用 instream.read(new byte[33554430], 0, 33554430); 读取整个文件,异常复现了,这次没有 seek(4) 方法调用,输出如下:
1 | 2021-11-27 22:01:36,758 INFO nat.NativeOssFileSystem (NativeOssFileSystem.java:open(435)) - Opening '/tmp/33554430' for reading |
这证明了异常与 seek(4) 没有直接关系,而是与读取的文件长度存在某种联系,文件大小为 33554430 字节时直接读取文件会触发异常,33554430 等于 32MiB 减去两个字节,即非常接近 32MB,于是我阅读了 BufferReader 的代码,因为几乎没有注释,所以是跟着调试读完这个类的代码的,记录的注释如下:
1 | /** |
BufferReader 的核心思想如下,根据文件大小创建一个缓冲区 buffer,在文件大小为 33554430 时,这个缓冲区的大小为 2097152 即 2MB,在默认配置下,会创建 4 个 ConcurrentReader 即 4 个读取线程去异步读取文件,我们将这四个线程命名为 reader-0, reader-1, reader-2, reader-3,其中,每个线程负责读取两个 half 的数据,我们将这两个 half 命名为 half-0, half-1,缓冲区最大容纳 8 个 half,给每个 half 划分的缓冲区可用空间大小为 2097152 / 8 = 262144,即对应代码中的 splitSize 字段,可以用如下示意图描述各个 reader 线程在缓冲区中各自负责的部分:
1 | -------------------------- buffer -------------------------- |
那么对于文件大小 33554430,每个 reader 需要读取 16 组 half,即 16 次 half-0 和 16 次 half-1,在本地调试过程中,我发现抛异常的都为 reader-3,且均为 reader-3 读取 half-1 时,对应图中 buffer 中的最右侧,那么这一块有什么问题呢?此时就要引出最关键的为每个 half 计算需要从流中获取数据的长度的代码,其中造成数组越界最关键的代码如下:
1 | else if ((long) (halfFetched + 1) * bufferSize / 2 >= lengthToFetch) { |
即在当前 half 的下一个 half 超出 lengthToFetch 时,在本例中,为 reader-3 即将读取 half1 时,即将读取最后一个 half,因为 2MiB 的 buffer 中单个 reader 需要读取 half-0 及 half-1 两个 half,所以在读取最后一个 half1 时,reader-3 已经读取了 31 个 half,此时将为 reader-3 的 half-1 计算 fetchLength。从上面的代码中,我们知道,如果此时是 reader-0 或 reader-1 或 reader-2,此时 fetchLength = (int) (lengthToFetch - (long) halfFetched * bufferSize / 2) / concurrentStreams = (33554430 - 31 * 2097152 / 2) / 4 = 1048574 / 4 = 262143.5 = 262143,当此时是 reader-3 时,fetchLength 会被重新计算为 fetchLength = (int) (lengthToFetch - (long) halfFetched * bufferSize / 2 - (fetchLength * (concurrentStreams - 1))) = 33554430 - 31 * 2097152 / 2 - (262143 * (4 - 1)) = 262145。为什么需要对 reader-3 重新计算呢?是因为使用剩余文件长度除以 reader 的个数时,可能存在除不尽的情况,那么对于前面几个 reader,负责读取的长度为抹掉小数点的值,即刚刚提到的 261243 字节,这部分除不尽的的小数部分最后都需要由 reader-3 来读取,即刚刚计算出的 262145 字节,在这里,就超出了预先给每个 half 分配的 splitSize 的大小,即超出了 262144,所以,reader-3 在使用 fetchLength = 262145 去流中读取数据时,底层流在读取前会检查传入的 buffer 能否容纳传入的 fetchLength,因为不能通过检查,就触发了数组索引越界异常,即我们之前看到的异常。
看到这里其实已经知道了问题所在,在定位问题的原因之后,解决方案有多种,我认为最简单的解决方案即在为 buffer 分配空间时多分配 concurrentStreams - 1 个字节,以存储因 concurrentStreams - 1 除不尽 concurrentStreams 这部分字节,因为这部分字节由最后一个 reader 的 half-1 读取。当然,也可以将整个 BufferReader 的设计进行一定的调整来解决该问题,此处不再一一分析。
经过该问题,我想到之前 Binary Search 一文中提到的观点:即使是最小的代码段也很难正确编写。单元测试无法覆盖所有的输入值也是一个原因,我们在程序设计时需要对各种输入值进行尽量完善的考虑以尝试避免类似问题的出现。