首先看一段存在 bug 的代码:
1 |
|
不知道大家能不能看出以上代码存在的问题,我第一眼看到的是第 27 行对 isolatedEndpointsSet 的读取操作没有加上读锁。其实还有另一个问题,那就是第 55 行会触发死锁,为什么呢?不是由另一个线程执行回调方法申请写锁吗?以上代码使用的 Guava 版本为 20.0,我们看下 Futures.addCallback 的源码:
1 | /** |
可以看出,注释进行了如下的说明:
This overload, which does not accept an executor, uses
directExecutor, a dangerous choice in some cases. See the discussion in theListenableFuture#addListenerdocumentation.
即该方法并没有接受一个 executor,而是使用的 directExecutor(),在某些情况下是一个危险的选择,可以查看 ListenableFuture#addListener 文档中的讨论。我们先看看 directExecutor() 的实现:
1 | /** |
可以看出 DirectExecutor 的 execute 方法实现为 command.run(),即直接用当前线程执行 run() 方法,与 CallerRunsPolicy 拒绝策略实现一样。我们再看看 ListenableFuture#addListener 的文档:
1 | public interface ListenableFuture<V> extends Future<V> { |
其中特意提到,当使用 MoreExecutors#directExecutor 时:
The listener may be executed by the thread that completes this
Future. That thread may be an internal system thread such as an RPC network thread. Blocking that thread may stall progress of the whole system. It may even cause a deadlock.
即阻塞该线程可能阻塞整个系统的进程,甚至可能造成死锁。正如文档所警告的,文首的代码在生产环境中触发了死锁。为什么会触发死锁呢?很简单,因为读锁与写锁互斥,在当前线程已经申请到读锁的情况下,再去申请写锁,将会触发死锁。这个问题在 ReentrantReadWriteLock (Java Platform SE 8 ) 中示例代码中进行了简短的描述:
1 | class CachedData { |
其中第 9 行提到:
Must release read lock before acquiring write lock
如果我们未按示例代码的说明进行操作,即在已申请到读锁的情况下去申请写锁,将会导致当前线程死锁。执行文首代码的线程是一个 Endpoint 健康检查的线程,这个线程因死锁导致永久阻塞后影响还不算大,那么现在我们讨论另一个问题,该线程进入死锁状态后,其他线程申请读锁还能申请到吗?起初我认为是能申请的,因为即使当前线程死锁,也是因为写锁申请阻塞,且因为写锁并未申请成功,不应该阻塞其他线程申请读锁才对。但是事实告诉我以上的理解并不完全正确。线上实例出问题时我正在外面吃饭,当时通过手机看到 Agent 自动抓取到的栈帧显示大量的线程阻塞在读锁申请上,我当时猜测有线程申请到了写锁且未及时释放导致,但是后面我用电脑查看堆转储时告诉我并没有线程申请到了写锁。我们使用 MAT 在当时事故现场抓取的堆转储中执行以下 OQL: SELECT * FROM com.aliyun.openservices.ons.shaded.org.apache.rocketmq.client.impl.producer.ProducerImpl:
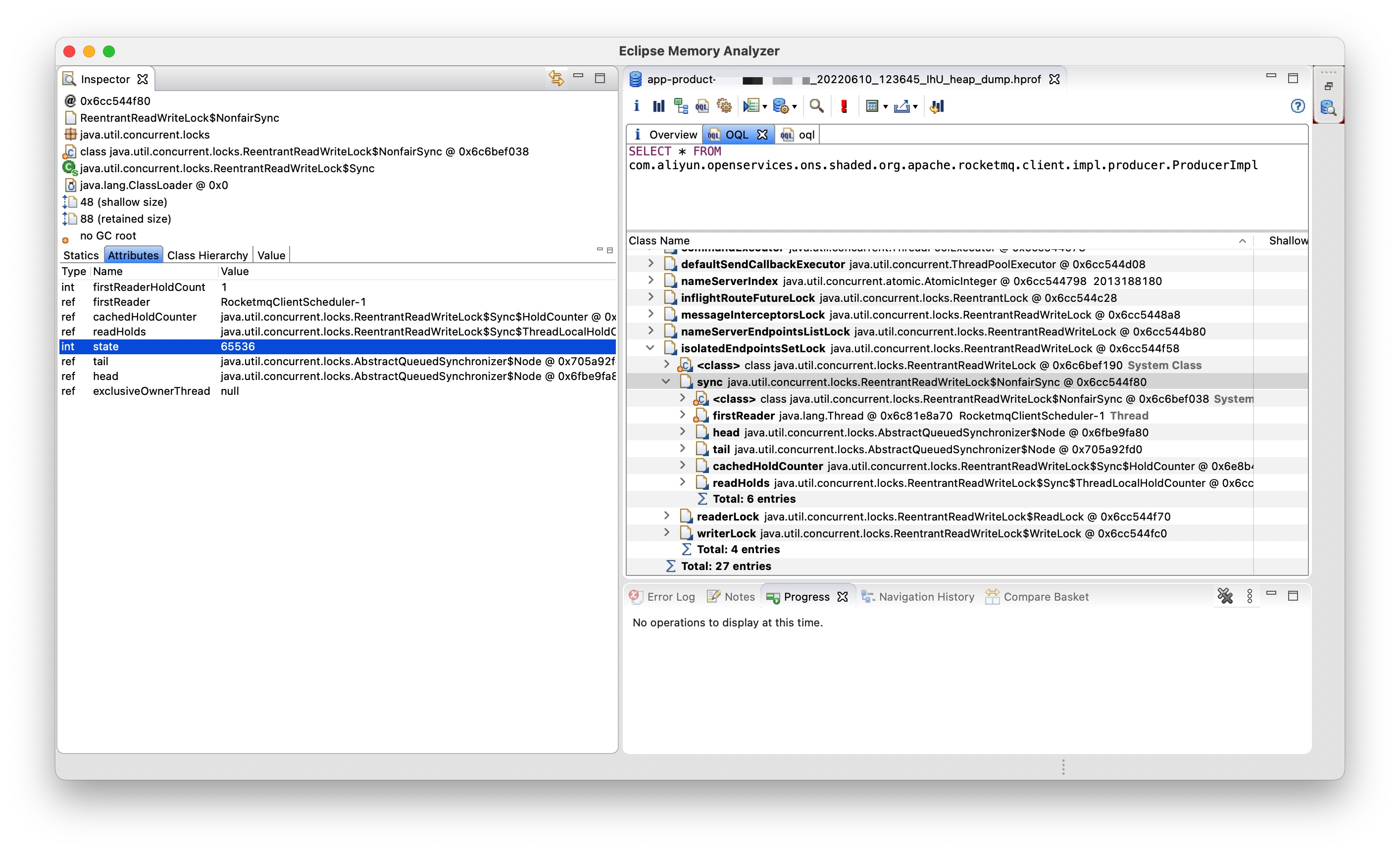
可以看出 isolatedEndpointsSetLock 这把锁的 state 值为 65536,对应的二进制表示为:00000000_00000001_00000000_00000000,我们知道高 16 位表示读锁的状态,低 16 位表示写锁的状态,即此时 isolatedEndpointsSetLock 仅有读锁被申请到了,且 firstReader 为 RocketmqClientScheduler-1,即我们文首分析的进入死锁状态的线程,我们也可以用线程转储来验证这一点:
1 | "RocketmqClientScheduler-1" #71 prio=5 os_prio=0 tid=0x00007f106ca8f800 nid=0x58 waiting on condition [0x00007f104b041000] |
即 RocketmqClientScheduler-1 线程申请到了读锁,在申请写锁的过程中被挂起,触发了死锁。而此时写锁并未申请成功,为何会阻塞其他读锁申请的线程呢?不是说读锁与读锁不互斥吗?我们再看看这把锁的等待队列:
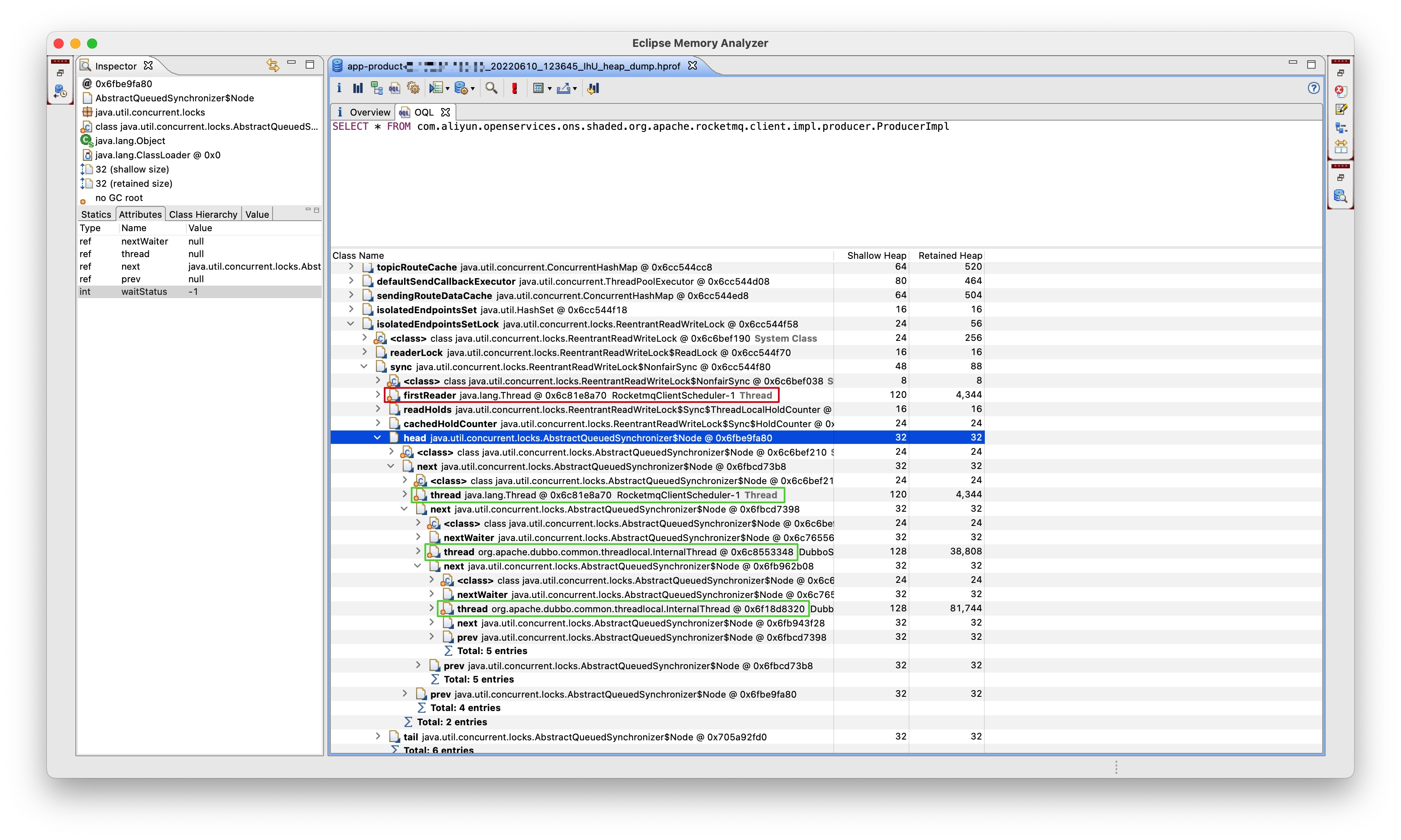
其中绿色的即为等待队列中各个节点对应的线程。即如下图所示:
1 | +----------------+ +-------------------------------+ +--------------------------+ +--------------------------+ |
即线程 RocketmqClientScheduler-1 处于队列中的首个节点(不含 dummy head),在等待自己释放读锁,而读锁需要申请到写锁后才能释放导致了死锁,导致线程 RocketmqClientScheduler-1 一直处于队列首个节点(不含 dummy head),而其他申请读锁的线程为何全部被阻塞挂起了呢?注意此时并没有任何线程持有写锁,按照读锁与写锁互斥的约定理论上读锁是应该能申请到的,但是实际上读锁并不能申请到,而是申请读锁的线程都被阻塞挂起了。我们再次回到文首的代码,可知创建读写锁是使用的这一行代码:this.isolatedEndpointsSetLock = new ReentrantReadWriteLock();,对应的源码如下:
1 | /** |
即创建的非公平读写锁,那么非公平读写锁在处理线程是否阻塞挂起的判断是怎样的呢,我们再看看 NonfairSync 的源码:
1 | /** |
在 readerShouldBlock() 方法的注释中已经解释得非常清楚了,这是一个启发式的方法,为了避免写锁饥饿,如果队首节点(不含 dummy head)中的线程是申请写锁的线程,则读锁申请应该阻塞以便让写锁优先申请。我们看看 apparentlyFirstQueuedIsExclusive() 方法的源码:
1 | /** |
该方法实现正如方法名所描述的,这也解释了在生产环境中遇到的问题,即不仅仅线程 RocketmqClientScheduler-1 被挂起了,其他申请读锁的线程全部被挂起了,导致相关线程池活跃线程数满,影响线上服务。在 ons-client 2.0.0.Final 和 ons-client 2.0.1.Final 中都存在该问题,这个问题在 ons-client 2.0.2.Final 中被修复,修复的方案简单粗暴,直接移除了读写锁实现,改为了线程安全的集合实现:
1 | this.isolatedEndpointsSet = Collections.newSetFromMap(new ConcurrentHashMap<Endpoints, Boolean>()); |
我们再看看读写锁为公平锁实现时判断锁申请是否应该阻塞的实现:
1 | /** |
公平锁的判断则相对来说较为简单,即判断等待队列中是否存在指向不为当前线程的节点,正如方法名所描述的,是否存在排队的前驱。
最后总结下文首代码导致线上服务不可用的几个关键因素:
- 使用了 Guava 的
Futures.addCallback方法,该重载版本使用的directExecutor导致写锁申请在持有读锁的线程中执行,触发了死锁 - 实例化
ReentrantReadWriteLock时采用的默认的构造函数,即非公平锁实现,该实现中的readerShouldBlock()方法为了避免写锁申请饥饿进行了启发式处理 - 由于某种执行次序导致
RocketmqClientScheduler-1写锁申请对应的节点处于等待队列的队首(不含 dummy head),导致其他进行读锁申请的线程全部被阻塞挂起
正是以上几个因素的共同作用导致了线上事故,我们查看 Guava 关于 Futures 的 changelog 可以发现使用 directExecutor 的 Futures.addCallback 方法在 2018-05-24 被标记为了 @DonotCall,于 2018-07-31 被移除,说明官方也认为该方法具有误导性,直接从 Guava 中移除了。相关 commit 可以参见:History for guava/src/com/google/common/util/concurrent/Futures.java - google/guava · GitHub。
References
Heap Dump - Concepts - Memory Analyzer
版本说明 - 消息队列RocketMQ版 - 阿里云
ConcurrentHashSet