最近查了个与 CLOSE_WAIT 状态有关的问题,在此简要记录。首先背景是在业务高峰期时由于同事误操作下掉了某组应用一半以上的后端服务器,导致流量全部打在剩余的后端服务器上,由于剩余的后端服务器不足以支撑所有的流量,接口响应时间开始增大,Tomcat 线程池中的活跃线程数迅速增加至 200,接着就是负载均衡侧对后端服务器的健康检查不能成功,检活失败次数达到设置的检活阈值后即自动将不健康的后端服务器进行了摘除,随着后端服务器的摘除,剩余的后端服务器更加不能支撑线上流量,最后导致该组应用的所有后端服务器被摘除。收到告警后同事立即增加了线上后端服务器实例个数,但是服务并没有恢复,不仅之前被负载均衡摘除的后端服务器没有及时恢复,新加入的后端服务器在短暂的服务后也被负载均衡判定为不健康随即被摘除。整个服务面临的情况就是在业务高峰期无法进行冷启动的问题,随即同事在应用层对相关核心接口进行了限流以尝试逐步恢复服务,但是接口限流后服务也没有立即恢复,而是在四十分钟后,服务逐步恢复。由于事故发生时我正在外面做核酸检测,所以并没参与处理此次线上事故。在该次事故后,我从事故发生时采集到的相关监控数据来尝试还原事故现场并分析服务不能快速恢复的原因。
首先从负载均衡侧的监控可以确认事故发生时 QPS 并没有突发增加,仅有小范围的抖动,且我们已知事故由同事的误操作导致后端实例需要承载高峰期双倍以上的流量导致。随即查看了负载均衡与用户侧的活跃连接数,发现自后端服务器不可用后负载均衡侧与用户侧的活跃连接数增加了十倍,且每秒新建连接数也同步增加,同时后端服务器上的连接数也有同步的增加,猜测因服务不可用导致用户侧大量重试以使以上指标出现了突增。除了网络相关的基础监控数据,同时还检查了 JVM 层面是否存在问题,确认没有发生 OOM,也没有 GC 相关的问题,在流量被摘除前 CPU 使用率有一定程度的升高,但是随着流量的摘除,CPU 使用率立即下降为接近 0 的状态,从事故发生时 Agent 多次抓取到的栈帧来看,均存在相同的模式,即 200 个以 http-nio-80-exec- 开头的 Tomcat 线程全部处于 TIMED_WAITING 状态,虽然这 200 个线程中部分线程栈帧底部存在差异,但是这 200 个线程的栈帧顶部完全一致,这部分重复的栈帧为:
1 | java.lang.Thread.State: TIMED_WAITING (parking) |
不难看出 Tomcat 这 200 个线程全部在等待 NioSocketWrapper 对应的 writeLatch,该组应用使用的 Tomcat 版本为 8.5.59,以上栈帧中 NioBlockingSelector 对应的源码位于 NioBlockingSelector.java at 8.5.59:
1 | /** |
根据此线索我查询了与 writeLatch 相关的代码,其中 writeLatch 的定义位于 NioEndpoint.java at 8.5.59:
1 | // ---------------------------------------------------- Key Attachment Class |
即在 NioSocketWrapper 中,定义了 readLatch 和 writeLatch 来控制 Socket 的读写,其数据结构为 CountDownLatch,而我们主要关注 writeLatch,所以暂不分析 readLatch 相关代码,而与 writeLatch 密切相关的代码即位于上方的 NioBlockingSelector#write 方法中,且我们重点关注以上代码片段中的 39-45 行:
1 | if ( att.getWriteLatch()==null || att.getWriteLatch().getCount()==0) att.startWriteLatch(1); |
从这部分代码片段可知,如果 NioSocketWrapper 未关联 writeLatch 或关联的 writeLatch 的 count 为 0 则会调用 att.startWriteLatch(1) 创建一个 count 为 1 的 CountDownLatch 实例作为该 NioSocketWrapper 的 writeLatch,用于控制是否对底层的的 Socket 进行写操作,随即调用了 poller.add(att,SelectionKey.OP_WRITE,reference) 方法在 NioBlockingSelector.java at 8.5.59 中异步注册对该 Socket 的可写的 Selection Operation 以表示对该 Socket 可写事件感兴趣。关于 SelectionKey.OP_WRITE,在 JDK8 中的注释如下:
1 | /** |
随即开始等待 writeLatch,在 Tomcat 的默认配置中,writeTimeout 为 20 秒,即在此处会等待 20 秒,回到之前提到的 NioBlockingSelector#write 方法,在该方法的注释中提到:
Performs a blocking write using the bytebuffer for data to be written
即将 bytebuffer 中的数据进行阻塞写,如果站在 NioBlockingSelector#write 整个方法的维度来看的话,这句注释是没有问题的,但是如果我们仔细看 NioBlockingSelector#write 方法的实现,不难发现,整个数据写入过程主要涉及 socket.write(buf) 与 att.awaitWriteLatch(writeTimeout,TimeUnit.MILLISECONDS),即通过 writeLatch 来协调何时进行写入,当不能写入数据时则在 writeLatch 上等待。而其中的 socket.write(buf) 方法,如果我们查阅 Tomcat 内部 NIO 实现的相关代码,不难发现此处的 Socket 是非阻塞的,我们可以通过源码和 debug 来验证,设置接收到的 Socket 的相关属性的代码位于 NioEndpoint.java at 8.5.59:
1 | /** |
可以看出在接收到的 Socket 上调用了 socket.configureBlocking(false),即将 Socket 设置为非阻塞,以便使用 Poll 来处理 Socket 的读写。我们也可以通过 debug 来验证:
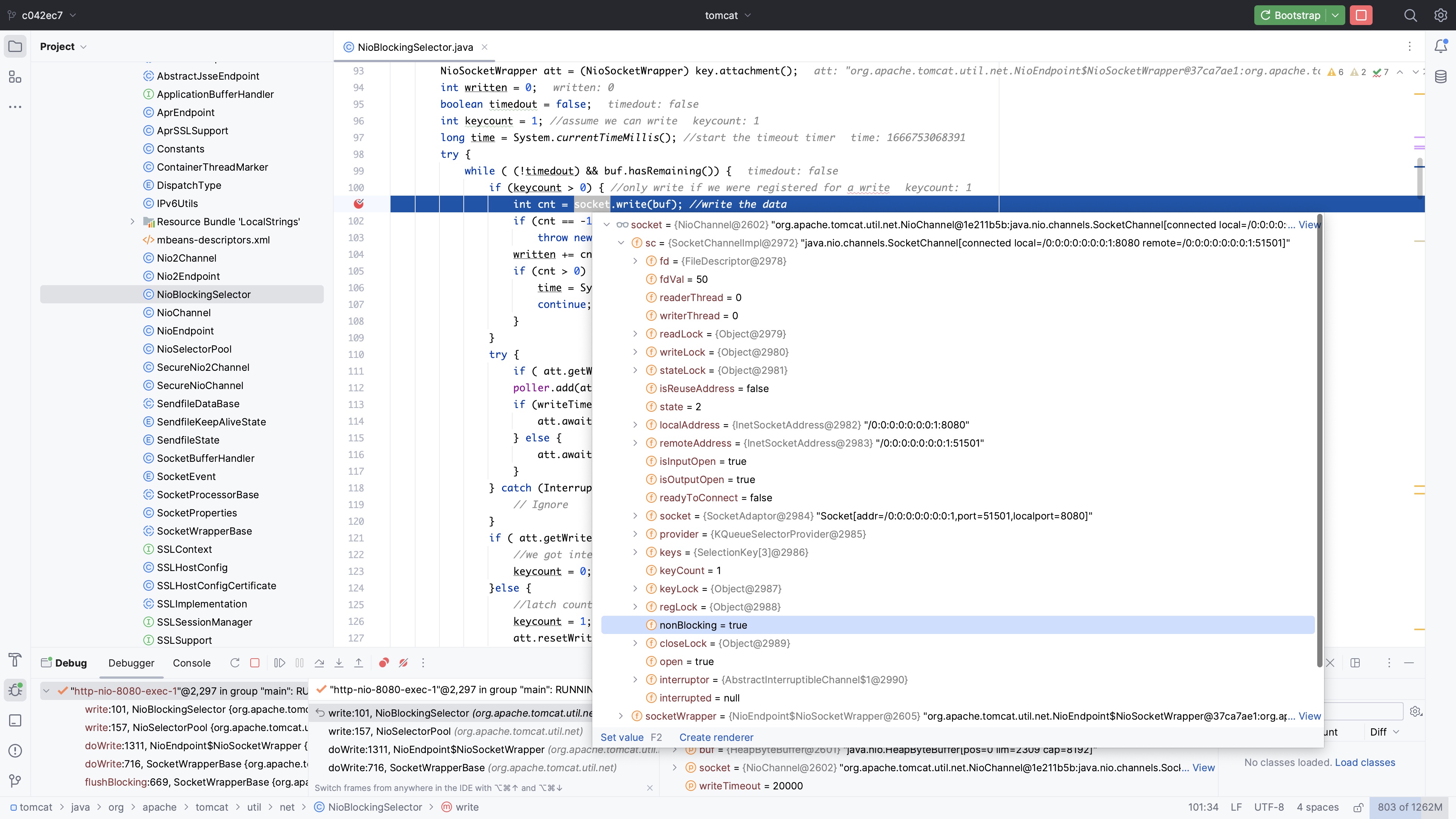
即服务端接收到的 Socket 均设置为了非阻塞模式。如果我们在 NIO 相关的包中搜索 .configureBlocking,不难发现仅有两处对是否阻塞进行了配置,搜索结果如下:

截图中选中的部分即我们刚提到的 Socket 上设置的非阻塞的逻辑,另一处设置阻塞模式为阻塞的代码位于 NioEndpoint.java at 8.5.59:
1 | /** |
此处的 serverSock 是用于接收连接的服务端的 Socket,可以看出此处设置的阻塞模式为阻塞,即在接受请求的 Acceptor 线程中,操作的 serverSock 是阻塞的。现在回到 NioBlockingSelector#write 方法的第二句注释:
If the
selectorparameter is null, then it will perform a busy write that could take up a lot of CPU cycles.
该注释提到,如果 selector 参数为空,则执行忙写,可能消耗大量 CPU 周期。而我们仔细观察 NioBlockingSelector#write 方法的参数,却发现并没有 selector 参数,如果查看 NioBlockingSelector 类的 提交记录,不难发现这段注释来自于 2007-02-21 的这次提交 Fix (may not be complete yet) to the memory leak in the NIO connector.,仔细查看该次提交修改的文件后,可知关于 selector 的这段注释是给 NioBlockingSelector#write 的重载方法编写的,而作者只是简单的复制了重载方法的注释,未对 selector 这段注释进行删除。所以我们暂且忽略这段注释,因为随着 Tomcat 版本的演进,重载的含有 selector 参数的 NioBlockingSelector#write 方法已经被移除了。
回到 NioBlockingSelector#write 方法主流程,通过阅读该方法的实现,我们可以确认该方法的处理逻辑为:当 while 首次进入时,如果 buf 存在未写出的数据,则尝试调用 socket.write(buf) 对 buf 中的数据进行写出,然后对 int cnt = socket.write(buf) 的返回值 cnt 进行判断,当 cnt 等于 -1 时,抛出 EOFException,当 cnt 大于 0 时,使用当前时间去更新 time 变量,并执行 continue; 进行下一次是否循环的判断,即当 buf 还有数据未写出时,会立即再次进行写出,而不会走下方与 writeLatch 相关的执行逻辑。我们看看刚刚提到的 socket.write 调用的 JDK8 中 WritableByteChannel#write 的方法注释,源码位于 WritableByteChannel.java :
1 | /** |
我们重点关注这一段:
Unless otherwise specified, a write operation will return only after writing all of the
rrequested bytes. Some types of channels, depending upon their state, may write only some of the bytes or possibly none at all. A socket channel in non-blocking mode, for example, cannot write any more bytes than are free in the socket’s output buffer.
即除非另有说明,写入操作仅在写入所有请求的字节后才会返回。某些类型的通道,根据它们的状态,可能只写入一部分字节甚至根本不写入。比如非阻塞模式的 Socket 通道不能写入比 Socket 输出缓冲区可用空间更多的字节。我们再看该方法关于返回值的说明:
The number of bytes written, possibly zero
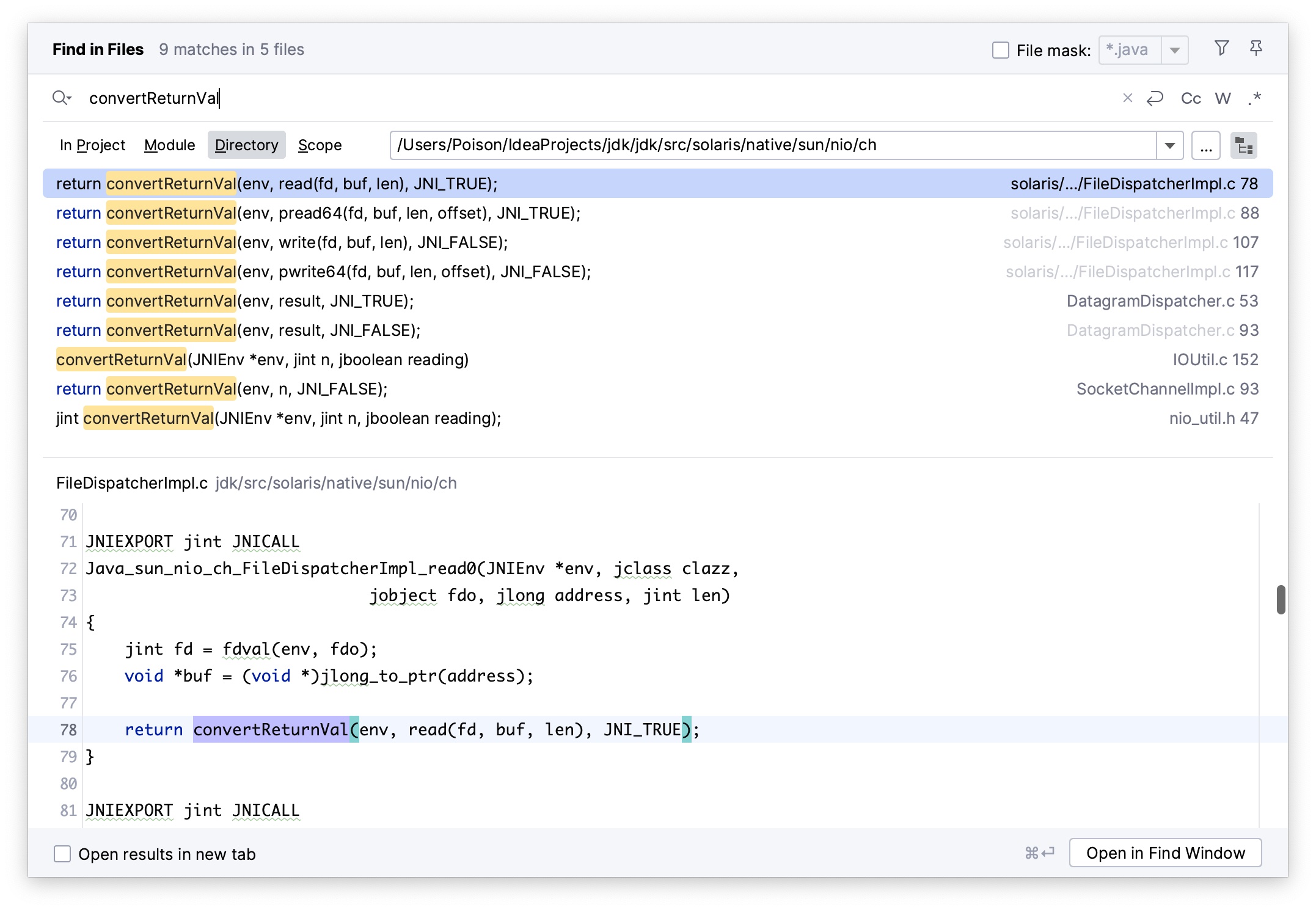
可知返回值为写入的字节数,可能为 0,但是在 NioBlockingSelector#write 方法实现的对 int cnt = socket.write(buf) 返回值 cnt 值的判断逻辑中,可以看出作者判断了两种情况,一种是 cnt 等于 -1 的情况,此时抛出 EOFException,另一种是大于 0 的情况,此时执行 continue; 继续尝试写入。此处关于 cnt 是否等于 -1 的判断是不需要的,作者可能不清楚 write 与 read 返回值的差异,亦或是 NioBlockingSelector#write 方法实现直接复制了 NioBlockingSelector#read 方法的实现且未删除关于 cnt 是否等于 -1 的判断。关于 write 是否会返回 -1 这个问题,首先我们从刚提到的 WritableByteChannel#write 方法的注释上没有看到有关于返回 -1 的说明,此外,我们可以从 OpenJDK 源码中来论证这一点,我们不断跟进 write 方法的实现,不难发现最终会调用至 FileDispatcherImpl.c:
1 | JNIEXPORT jint JNICALL |
其中 convertReturnVal 方法的实现位于 IOUtil.c:
1 | /* Declared in nio_util.h for use elsewhere in NIO */ |
不难发现 -1 仅在读取的情况下返回,我们再在 solaris nio 的目录中搜索对 convertReturnVal 的调用,可知来自 write 的调用传入的 reading 参数均为 JNI_FALSE,来自 read 的调用传入的 reading 参数均为 JNI_TRUE。
既然分析到了这里,我们提交一个 PR 优化一下对 cnt 是否等于 -1 的判断:Remove unnecessary -1 predicate because write will not return -1 unless NioChannel is CLOSED_NIO_CHANNEL by tianshuang · Pull Request #562 · apache/tomcat · GitHub。和往常一样,Mark 稍作优化,增加了 changelog 并单独进行了提交:NIO writes don’t return -1 so neither should CLOSED_NIO_CHANNEL · apache/tomcat@cc7c129 · GitHub。
我们再次回到之前提到的 NioBlockingSelector#write 方法,根据以上的分析,易知在 while 循环中仅会当 int cnt = socket.write(buf) 返回的 cnt 的值为 0 时才会执行 writeLatch 相关的逻辑,即因为文档中提到的 Socket 输出缓冲区满等原因无法写入时,返回的 cnt 值为 0,此时如果该 NioSocketWrapper 上未关联 writeLatch 或关联的 writeLatch 的 count 为 0,则会在该 NioSocketWrapper 上关联一个新的 count 为 1 的 writeLatch,接着异步注册对该 SocketChannel 可写操作感兴趣的事件,接着就在该 writeLatch 进行最长 20 秒的等待。因为 writeLatch 底层实现为 CountDownLatch,所以我们看看 CountDownLatch#await(long, java.util.concurrent.TimeUnit) 的注释,源码位于 CountDownLatch.java:
1 | /** |
根据注释易知当前线程会持续等待直到闩的计数器被 count down 至 0,除非当前线程被打断或者指定的等待时间 timeout 已经过去。如果调用该方法时闩的计数器已经为 0 则该方法会立即返回,如果闩的计数器大于 0,则当前线程则会被禁用调度并处于休眠状态直到以下三种情况之一发生:
- 由于 countDown 方法被调用导致计数器值变为 0
- 某个其他线程打断了当前线程
- 指定的等待时间已经过去
我们接着分析 NioBlockingSelector#write 剩余的部分,即 att.awaitWriteLatch(writeTimeout,TimeUnit.MILLISECONDS); 这一行执行后,根据以上注释可知,有以上三种情况,然后对 writeLatch 是否被 countDown 进行了判断,如果在 await 过程中线程被打断了或者在指定的等待时间内都没被 countDown,那么此时设置 keycount 为 0 以使若进入下一次 while 循环则继续等待而不再调用 socket.write(buf),因为底层的 Socket 未收到可写的事件,如果 writeLatch 被 countDown 了,则将 keycount 设置为 1 以使下一次进入 while 循环时能够调用 socket.write(buf),因为底层的 Socket 此时可写了,同时还调用了 att.resetWriteLatch() 将关联的 writeLatch 置为空以便下一次进入 while 循环后重建新的 writeLatch。接着还有一个对超时时间的判断,当距离上一次写入时间超过 Tomcat 设置的 writeTimeout 且本次未等到可写事件时,将跳出循环并抛出 SocketTimeoutException,最后在 finally 中执行了一些清理操作。以上是 NioBlockingSelector#write 方法的实现逻辑。
那么根据以上的分析,且 Agent 多次抓取的栈帧中 200 个 Tomcat 线程全部停在 att.awaitWriteLatch(writeTimeout,TimeUnit.MILLISECONDS),可以大胆猜测为文档中提及的 Socket 写入缓冲区满导致返回的 cnt 为 0 而使 http-nio-80-exec-* 线程等待。那么现在需要排查的是:写入缓冲区满的原因是什么?为何流量全部摘除四十分钟后才能恢复服务?
带着以上这些疑问进一步分析,因为同事未在事故现场抓取堆转储,导致我们丢失了很多有用的信息,而 Agent 抓取的栈帧已不能提供更多的信息,所以我尝试复现该问题以收集更多的信息。而根据以上的分析已知与 Socket 发送缓冲区满有关,所以我主要选择了一些响应数据尽可能大的接口来进行压测,在经过多次尝试后,终于在一个业务接口上复现了该问题。监控到的 Tomcat 线程数变化如下:
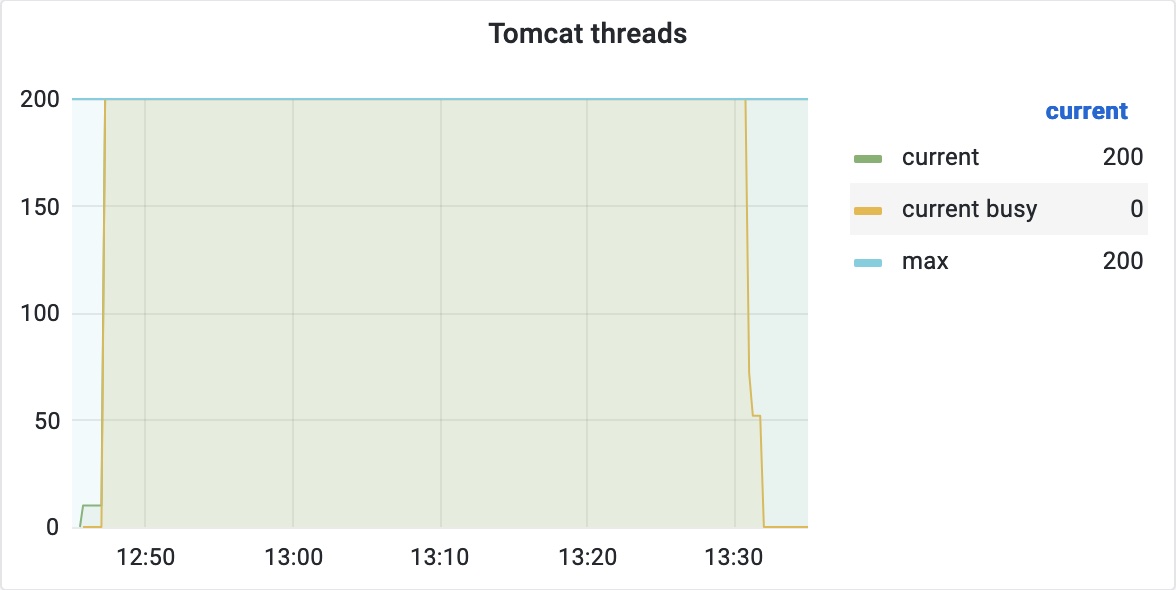
即当 12:48 负载均衡检活失败,摘除了后端服务器,且不再有新的 HTTP 流量进入后,线程数并未立即下降,而是持续四十分钟左右才下降。所以我们需要明确的是这四十分钟内后端服务器在处理什么。在确认可稳定复现该问题后,我使用 tcpdump 在后端服务器上抓取了这段时间的包进行分析,首先明确了负载均衡与后端服务器的通讯协议为 HTTP 1.1,且在每次请求中显式指定了 Connection: close,即可理解为负载均衡与后端服务器通讯每次新建了连接,且每次请求响应结束后关闭了连接。通过观察流量摘除后后端服务器依然不能提供服务这段时间段的包可以发现一个规律,即后端服务器往负载均衡写入响应数据时,数据包在不停重传,下面是一个典型的 TCP Stream:
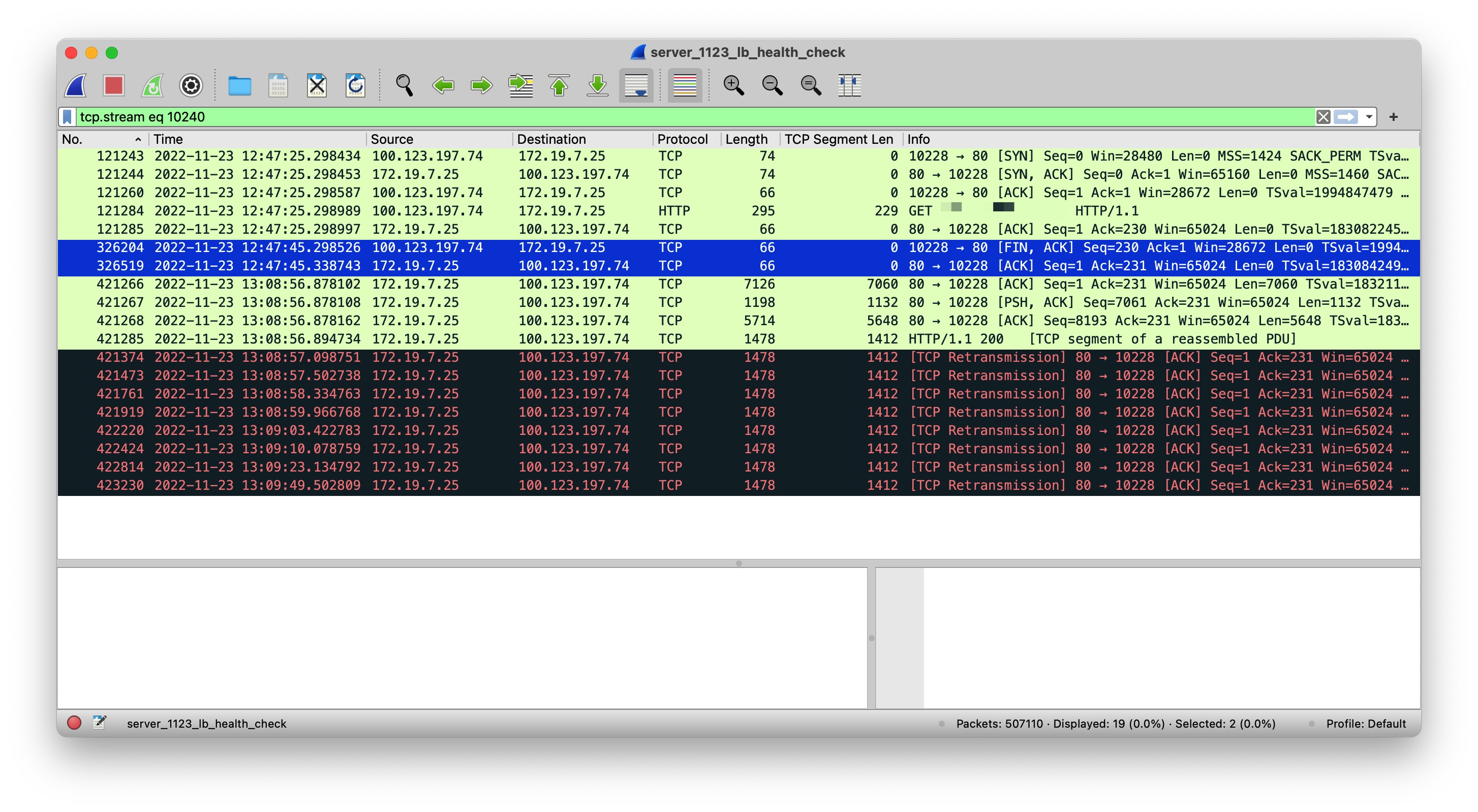
这是一个非常典型的 TCP Stream,可以看出编号为 326204 的 FIN 包于 12:47:45 由负载均衡发往后端服务器,随即后端服务器操作系统立即响应了 ACK 包,即编号为 326519 的包。这两个包在图中为蓝色,如果我们仔细观察这两个包与之前、之后的包的时间间隔,不难发现编号为 326204 的 FIN 包的前一个包,即编号为 121285 的包(时间:12:47:25),时间相差了 20 秒,那么这 20 秒代表什么含义呢?这里直接给出结论吧,经过验证,这 20 秒是负载均衡层配置的后端服务器的请求超时时间,即后端服务器未在负载均衡层配置的请求超时时间内返回数据的话,此时负载均衡会主动发送 FIN 包至后端服务器。接着看编号为 326519 这个包的后面一个包,即编号为 421266 的包(时间:13:08:56),可知时间相差了 20 分钟,那么这 20 分钟内又发生了什么呢?这里也直接给出结论,这段时间任务在 TaskQueue 中排队,关于 Tomcat 的任务提交队列机制可参考:Executor of Tomcat。即 Tomcat 的整体设计为优先创建线程去处理任务,当线程池满后,任务进入队列(特指线程池满的场景下,实际上存在空闲线程时任务也会提交至队列),我们也可以用这段时间内抓取到的堆转储来验证:
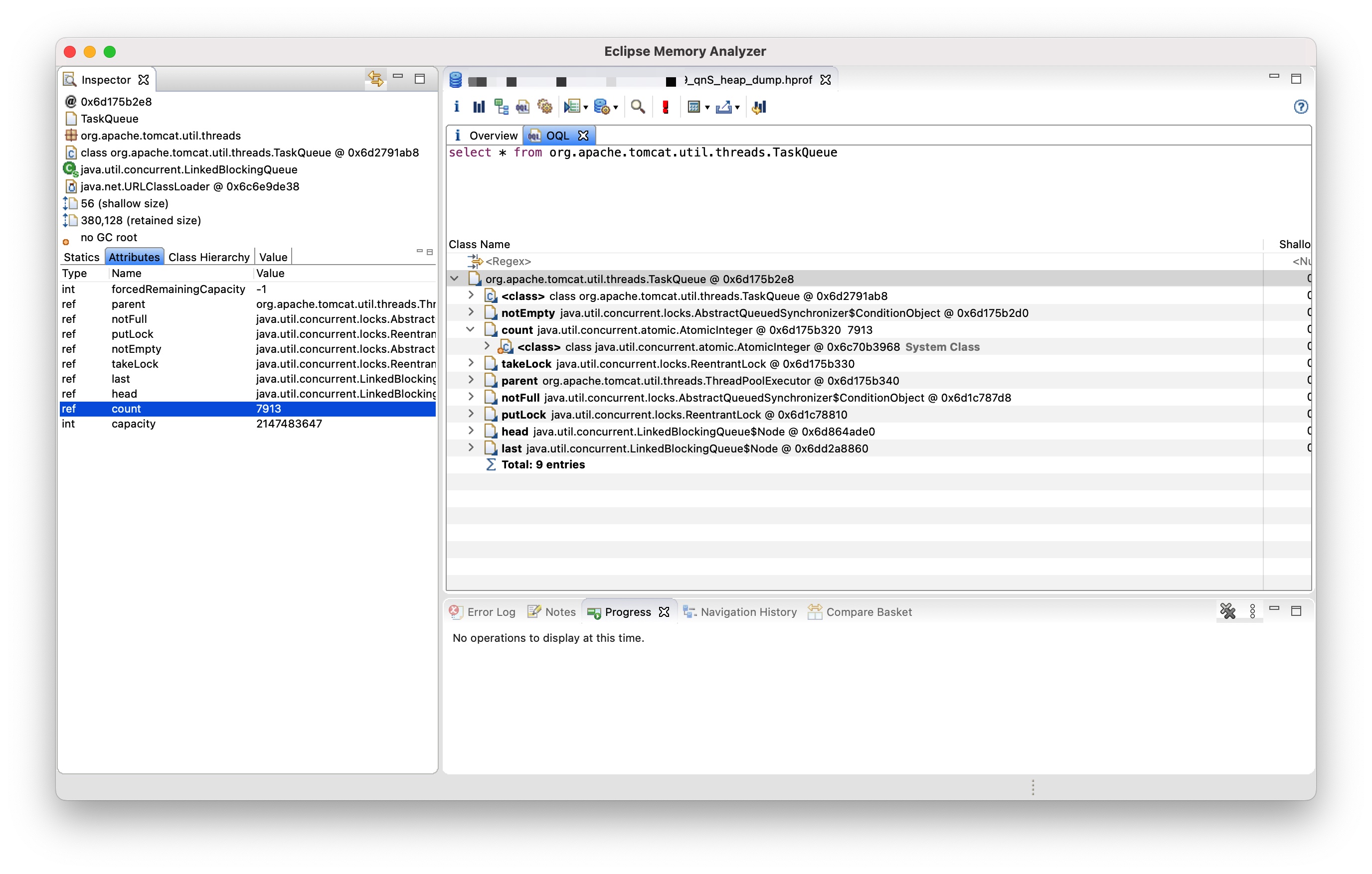
该堆转储在后端服务器刚被摘除不久后抓取,可以看出此时 TaskQueue 中的任务数为 7913,且 capacity 为 2147483647,即容量为默认配置:Integer.MAX_VALUE,如果跟随队列的 head 指针,则可以发现堆积的待处理的任务。那么为何图中这次请求会排队 20 分钟之久呢?我们继续看上面捕捉到的 TCP Stream,不难发现在后端服务器自 13:08:56 往负载均衡写入了几个包后随即开始了重传,且自 13:08:56 开始,负载均衡未响应任何数据包。到此时似乎应用层的等待与 TCP 包重传存在某种关系,于是我继续在抓取到的包中分析,随即发现了另一种模式,其典型的 TCP Stream 如下:
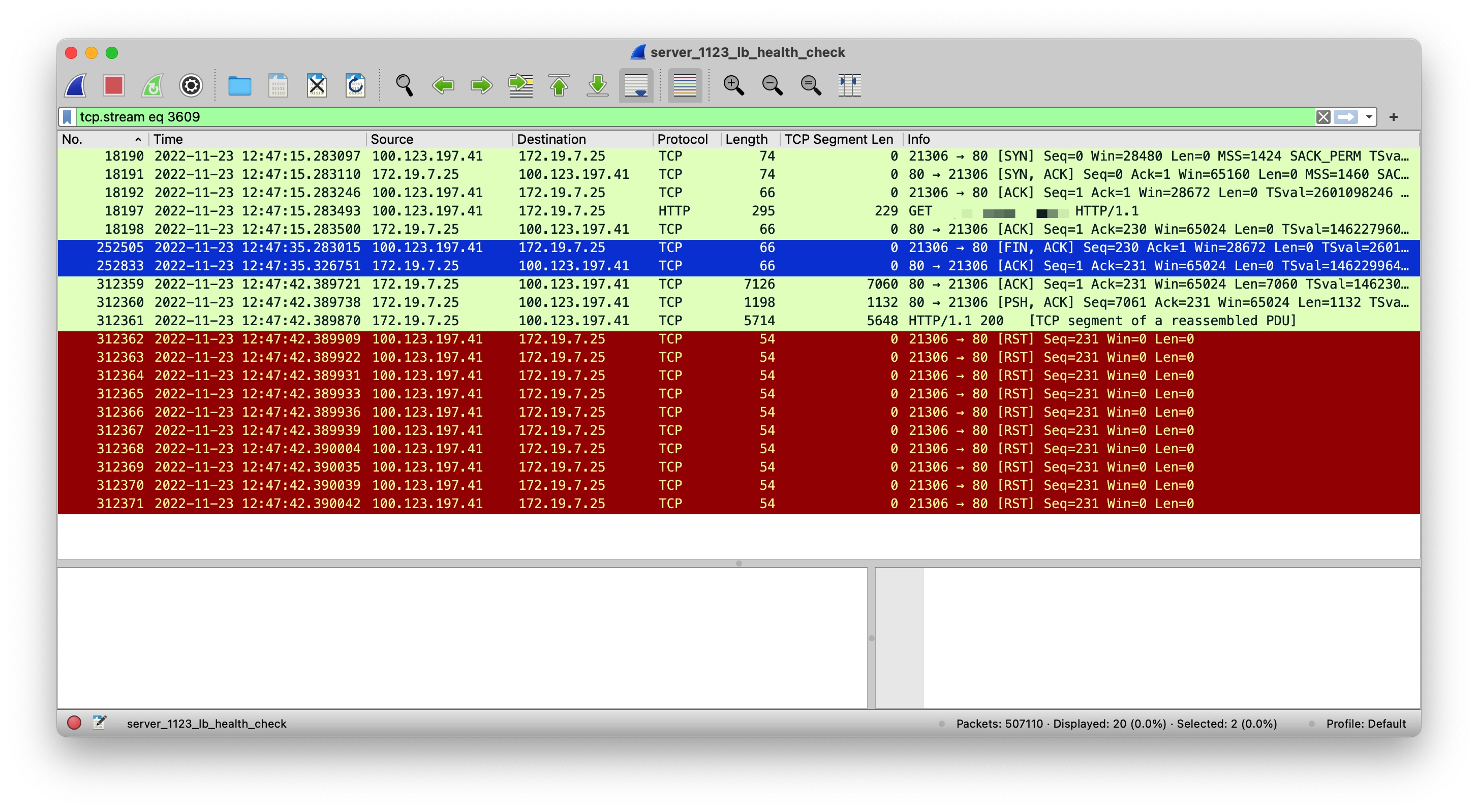
该 TCP Stream 与之前提到的 TCP Stream 类似,也是因为后端服务器未在 20 秒内响应数据,负载均衡向后端服务器发送了 FIN 包,后端服务器操作系统随即响应了 ACK 包。不同的是,当后端服务器尝试写回响应相关的数据包时,此时负载均衡侧响应了 RST 包,而并不像上文分析的那次请求。那么负载均衡响应行为为何不同?经过近一步分析,确认了此处存在一个时间窗口,即负载均衡向后端服务器发送 FIN 包后,此时后端服务器操作系统会立即响应 ACK 包,从此时开始计时:
- 如果在 16 秒内后端服务器响应了数据包,负载均衡会立即响应 RST 包
- 如果在 16 秒后后端服务器响应了数据包,负载均衡不响应任何数据包
我们可以看一个刚超过时间窗口的 TCP Stream:
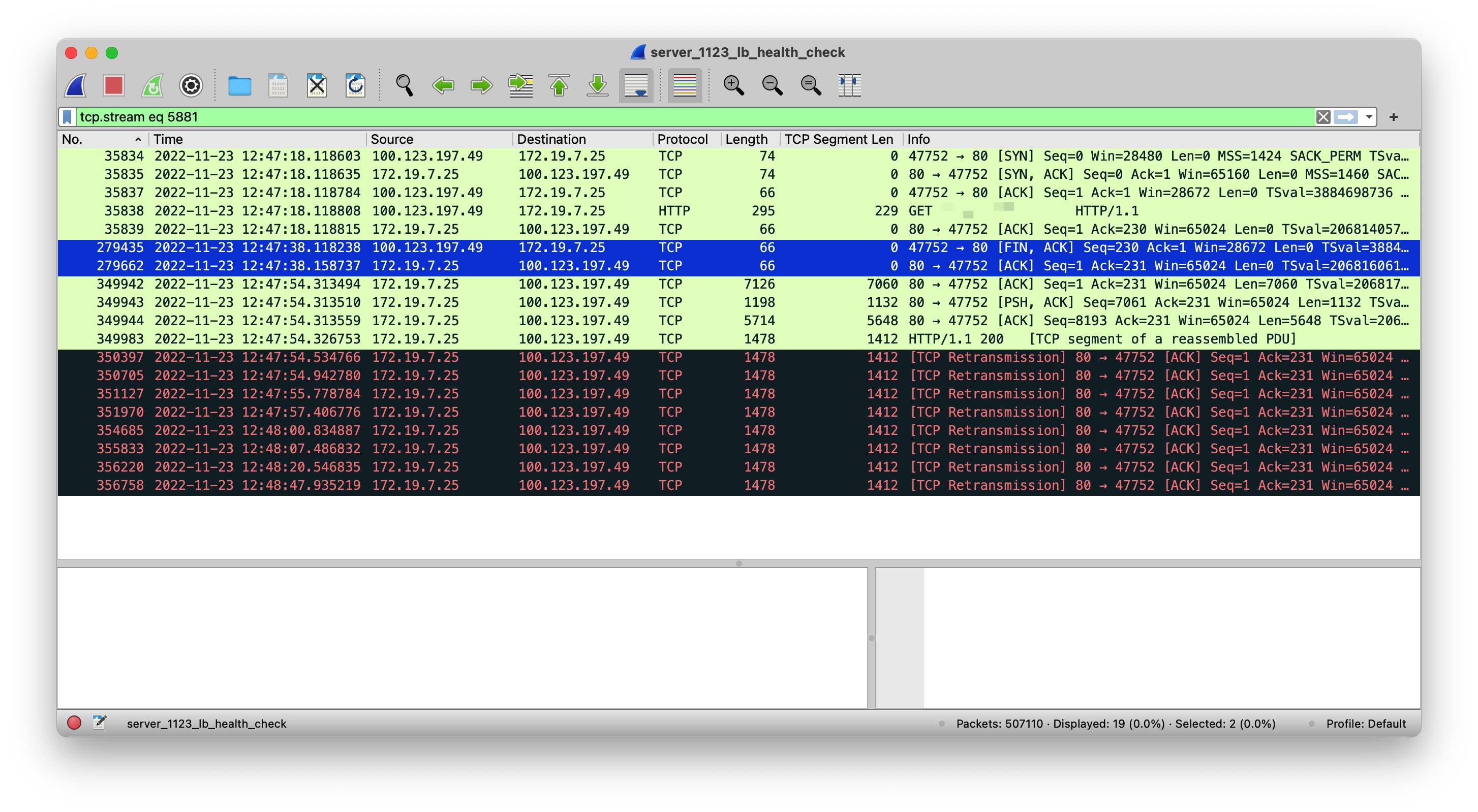
该 TCP Stream 中的后端服务器中写入的响应数据包在 FIN/ACK 包 16 秒后发出,此时负载均衡不会再响应任何数据包。因为负载均衡为云上的服务,所以暂时无法查看负载均衡的内部实现,关于 FIN/ACK 包 16 秒后负载均衡不响应数据包的原因,我个人更倾向是防火墙 DROP 了后端服务器向负载均衡写回的响应数据包。因为负载均衡选择的客户端端口会随着 TCP 连接的打开而对后端服务器开放,随着 TCP 连接关闭而不再对后端服务器开放,而 FIN/ACK 包是四次挥手的开始,所以我个人的猜测为此处存在类似防火墙的机制,当 FIN/ACK 包过去 16 秒后,防火墙不再开放负载均衡所用到的客户端端口,即将后端服务器写回给负载均衡的响应数据包丢弃,导致后端服务器写回的响应不能得到 RST 响应,而是持续重传。
回到持续四十分钟不能提供服务这个问题上,在后端服务器被负载均衡摘除后不久,我们执行 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 可以观察到以下 TCP 连接数状态分布:
1 | LAST_ACK 241 |
可知大量连接停留在 CLOSE_WAIT 状态,且不停执行以上命令,观察 CLOSE_WAIT 下降非常缓慢,下降至 0 需要四十分钟。结合如下这张 TCP 状态转换图:

可知 CLOSE_WAIT 状态属于被动关闭,即我们之前分析的 FIN/ACK 所触发转换而来,而大量连接处于 CLOSE_WAIT 状态也与我们之前的分析吻合,即负载均衡因为 20 秒未收到后端服务器的响应,发送 FIN 包至后端服务器,后端服务器操作系统响应 ACK 包,后端服务器上的 TCP 连接由 ESTABLISHED 状态转换为 CLOSE_WAIT,但是此时大部分 Socket 任务都在 TaskQueue 中排队,Tomcat 200 个线程全部处于 TIMED_WAITING 状态,无法实时处理队列中堆积的请求。而为何排队时间如此之长呢?对于单个连接,当负载均衡不响应 RST 包时,Tomcat 的线程会等待多久呢?起初我认为是 NioBlockingSelector#write 中的 writeTime 的值 20 秒,但是经过验证,实际上 NioBlockingSelector#write 抛出 SocketTimeoutException 后,后续的处理逻辑中还有两处触发了对 Socket 的写入,即单个线程因为负载均衡未响应 RST 包而等待的时间为 20 + 20 + 20 = 60 秒。下面给出这三次写入导致线程等待的栈帧:
首次等待的栈帧:
1 | java.lang.Thread.State: TIMED_WAITING (parking) |
第二次等待的栈帧:
1 | java.lang.Thread.State: TIMED_WAITING (parking) |
第三次等待的栈帧:
1 | java.lang.Thread.State: TIMED_WAITING (parking) |
如果使用 diff 工具比较这三次栈帧,则不难发现第二次触发等待的写入来自 ErrorReportValve#invoke 方法中的 response.flushBuffer(); 调用,而为何首次 SocketTimeoutException 抛出后线程没有因为异常而结束呢?通过查询代码,确认在 Tomcat 的源码实现中,在 SocketOutputBuffer#doWrite 中对异常进行了 catch 做简单的处理后将异常重新抛出,随即到达 OutputBuffer#realWriteBytes 方法,将异常进行了 catch 并包装为 ClientAbortException 继续抛出,随即到达 DispatcherServlet#doDispatch 方法,在此方法中 ClientAbortException 实例被捕获并被赋值至 dispatchException,随即在 processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException); 调用中,异常被重新抛出,并被 DispatcherServlet#doDispatch 方法再次捕获并在 triggerAfterCompletion(processedRequest, response, mappedHandler, ex); 调用中再次被抛出,接着在 FrameworkServlet#processRequest 中 ClientAbortException 再次被捕获并被重新抛出,接着在 ApplicationFilterChain#internalDoFilter 被 catch 并继续抛出,经过多次类似的处理,最终 ClientAbortException 异常在 StandardWrapperValve#invoke 中被捕获且未被重新抛出,这部分代码位于 StandardWrapperValve.java at 8.5.59:
1 | /** |
即在 ClientAbortException 被 catch 后,将该异常设置至 request 的属性中,并设置响应状态码为 500,同时设置响应错误标记。线程继续执行,直到 ErrorReportValve#invoke 方法中的 response.flushBuffer();,即第二次触发等待的写入调用,此部分源码位于 ErrorReportValve.java at 8.5.59:
1 | /** |
如果查看最新的 Tomcat 代码,会发现这块逻辑已经进行了调整,在 2021-02-25 的这次提交:Avoid attempting to write an error report if I/O is not allowed 中调整了这部分逻辑实现,调整后的代码为:
1 | /** |
即在调用 response.flushBuffer(); 前对是否允许 IO 操作进行了判断,若当前响应不再允许 IO 操作了,则不再调用 response.flushBuffer(); 了,避免了不必要的等待,而关于该响应的 ioAllowed 标记,是在哪里设置的呢?经过查询,发现自 NioBlockingSelector#write 中抛出 SocketTimeoutException 后,异常经过层层上抛,最终于 SocketOutputBuffer#doWrite 方法中作为 IOException 被捕获:
1 | /** |
在捕获了 IOException 后的处理逻辑中,执行了 response.action(ActionCode.CLOSE_NOW, ioe);,随即将异常再次抛出,ActionCode.CLOSE_NOW 对应的事件处理逻辑为:
1 |
|
根据注释 Prevent further writes to the response 可知,需要阻止对响应的进一步写入,即在 setSwallowResponse 方法调用中将关联的 outputBuffer 实例的 responseFinished 设置为 true 防止后续的进一步写入。接着调用了 setErrorState 方法将错误状态设置为 ErrorState.CLOSE_NOW:
1 | /** |
即传入的错误状态若比当前的错误状态更严重,则将当前的错误状态更新为传入的状态,在刚才的场景下,初始的错误状态为 ErrorState.NONE,SocketTimeoutException 异常发生后,传入的错误状态为 ErrorState.CLOSE_NOW,关于该错误状态的枚举定义为:
1 | public enum ErrorState { |
即 CLOSE_NOW 枚举实例的 ioAllowed 为 false,不再允许 IO 操作。即在 Tomcat 8.5.64 的 ErrorReportValve#invoke 实现中,在调用 response.flushBuffer(); 前对 ioAllowed 进行了检查,若不再允许 IO 操作了,则不再调用 response.flushBuffer(); 了,这样就规避了 SocketTimeoutException 异常发生后的第二次尝试写入。而在该组应用使用的的 Tomcat 8.5.59 中是没有该检查的,即触发了 SocketTimeoutException 后再次尝试写入导致了不必要的等待,且在再次抛出 SocketTimeoutException 异常后,异常经过层层上抛最终于 ErrorReportValve#invoke 中的 catch (Throwable t) 被捕获,随即执行了 ExceptionUtils.handleThrowable(t):
1 | /** |
即由 SocketTimeoutException 包装成的 ClientAbortException 会被静默吞掉,导致线程不能因为异常结束,从而继续往下执行。接着就触发了第三次的等待,第三次等待的写入来自 Response#finishResponse 调用,即 Container 中的 Pipeline 处理完后,将执行 response.finishResponse(); 尝试写入 outputBuffer 中剩余的字节,此处也造成了不必要的等待。而如果查看最新版的 Tomcat 代码实现,不难发现在 Fix bz 65137 Don’t corrupt response on early termination 这次提交中,对出现 SocketTimeoutException 后的处理逻辑进行了调整,调整后的逻辑为如果写入过程中因为写入超时触发了 SocketTimeoutException,则会记录下该 SocketTimeoutException,若后续尝试继续往该 Socket 写入数据,则会使用之前的异常创建一个 IOException 并抛出,防止了线程不必要的等待,这部分修复后的代码位于 NioBlockingSelector.java at 8.5.64:
1 | /** |
该修复方案本是为了修复 65137 – Invalid chunk encoding in the tomcat answer 这个 bug 而实现,但是对于我们这种场景依然适用,感兴趣的可以点击链接查看该 bug,此处不对 65137 这个 bug 做过多讨论。
分析到这里,我们已经找到文首提到的 200 个 Tomcat 线程顶部栈帧一致的原因,即不同线程的 NioBlockingSelector#write 来自以上三处不同的调用,而后两次不必要的调用在新版本的 Tomcat 实现中已经修复了。
根据之前的分析,我们知道,socket.write(buf) 返回的 cnt 为 0 会导致 Tomcat 线程等待,现在我们需要进一步明确在什么情况下返回的 cnt 会为 0。在 write 方法上存在以下注释:
A socket channel in non-blocking mode, for example, cannot write any more bytes than are free in the socket’s output buffer.
根据此注释,我们可以猜测写入的字节数超过了 Socket 的输出缓冲区。这也间接应证了文首提到的部分接口无法复现的现象,因为仅有少部分接口响应的数据可以填满 Socket 输出缓冲区,而对于响应数据未超过 Socket 输出缓冲区的请求,因为 Socket 为非阻塞模式,响应数据写入至输出缓冲区后就返回了,cnt 不会为 0,即使后续操作系统 TCP 层面存在重传,也不会导致 Tomcat 线程等待。而对于响应数据大于 Socket 输出缓冲区的这部分请求,如果负载均衡侧未作任何响应,我们可以猜测因没有负载均衡侧的 ACK 包导致输出缓冲区无法释放新的空间,从而写入一定字节数后 Socket 输出缓冲区一直处于满的状态,导致后续的写入都返回了 0,使 Tomcat 线程等待。
接下来我们确认下 Socket 输出缓冲区的大小,首先明确的是我们未在 Tomcat 配置中设置过 SO_SNDBUF,即使用的默认配置,因为发送缓冲区的大小在整个连接阶段是可能调整的,通过在堆积的这个时间段执行 ss -tm 可以发现这部分 CLOSE_WAIT 连接的发送缓冲区全部为 87040 字节,即 85 KiB:
1 | CLOSE-WAIT 230 0 [::ffff:172.19.7.25]:http [::ffff:100.123.197.124]:2082 |
该组应用的宿主机操作系统为 Ubuntu 18.04.6 LTS,内核版本为 4.15.0-139-generic,于是检出对应的源码以进一步排查关于 TCP 发送缓冲区的问题,源码检出可参考 Ubuntu。经过查询 TCP 连接建立相关的源码,确认发送缓冲区初始值位于 net/ipv4/tcp.c:
1 | /* Address-family independent initialization for a tcp_sock. |
该值在宿主机上为 16 KiB,可参考 tcp_wmem。在 TCP 连接建立后随即对发送缓冲区的大小进行了调整,代码位于 net/ipv4/tcp_input.c:
1 | /* 3. Try to fixup all. It is made immediately after connection enters |
即当 Socket 未显式设置 SO_SNDBUF 时将调用 tcp_sndbuf_expand 对 TCP 发送缓冲区进行扩张:
1 | /* Buffer size and advertised window tuning. |
注释部分为我根据 SystemTap 探测到的连接建立时的变量值,主要逻辑即根据协商的 MSS 加上部分 header、进行 2 的 n 次幂对齐等操作,并乘以一定倍数得到新的发送缓冲区大小,且不能超过系统的最大发送缓冲区大小。至此我们明确了在该宿主机上来自负载均衡的 TCP 连接建立后的后端服务器侧的发送缓冲区大小为 87040 字节。在此基础上,使用 SystemTap 确认了对于负载均衡不响应任何包的这部分请求,发送缓冲区自 TCP 连接创建后调整为 87040 字节后未再进行过扩张。那么是否意味着在负载均衡侧不响应 TCP 包的情况下,应用层写入 87040 字节后发送缓冲区就满了呢?于是我用 Sysdig 对 TCP 写入进行了查看,一个典型的请求所调用的 write 序列如下:
1 | 10725946 22:43:10.345157253 3 http-nio-80-exe (25520.25644) > write fd=78(<4t>100.123.197.72:3158->172.19.7.25:80) size=8192 |
可以看出前 10 次的写入都是成功的,每次写入了 8192 字节,而第 11 次时尝试写入 8192 字节,但是仅写入成功了 2520 字节,第 12 次时尝试写入 5672 字节,此时返回 EAGAIN,最后再尝试了两次,每次间隔 20 秒,均返回了 EAGAIN。那么根据以上的分析,可知应用层共写入了 8192 × 10 + 2520 = 84440 字节,与我们观测到的 TCP 发送缓冲区大小 87040 字节并不一致,那么不一致的原因是什么呢?继续跟进内核中的相关源码,发现应用层的数据写入传输层最核心的方法位于 net/ipv4/tcp.c:
1 | int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) |
其中较为关键的判断是否需要等待发送缓冲区的方法为 sk_stream_memory_free:
1 | static inline bool sk_stream_memory_free(const struct sock *sk) |
即可以看出是使用 sk->sk_wmem_queued 与 sk->sk_sndbuf 进行比较,根据我们之前的分析,易知 sk->sk_sndbuf 的值为 87040,那么只要 sk->sk_wmem_queued 大于等于 87040 即会触发执行 goto wait_for_sndbuf;,如果查询 sk->sk_wmem_queued 的累加逻辑,不难发现该值的累加不少都是基于 skb->truesize,如在 skb 入队代码中:
1 | static void skb_entail(struct sock *sk, struct sk_buff *skb) |
关于 skb->truesize,继续查询相关源码可发现在 skb 申请时进行了设置:
1 | /* return minimum truesize of one skb containing X bytes of data */ |
1 | /* Account for allocated memory : skb + skb->head */ |
注释说明了包含 skb 需要申请的内存加上 head 占用的内存,如果继续查看非线性数据区写入的方法如 skb_copy_to_page_nocache,会发现 sk->sk_wmem_queued 累加的值为 copy 的值,分析到这里,就不难解释实际可写入的字节数小于 87040 的原因了。下面用一份较详细的写入调用链路来进一步明确应用层数据写入传输层的流程:
1 | time: 1669732990, line 1295@tcp.c, sk->sk_write_queue->qlen: 0, sk->sk_write_queue->tail address: ffff8a210074a358, size_goal: 14120 |
我们仔细分析以上这次写入调用链路,不难发现,首次到达 line 1295@tcp.c 时,发送队列的长度为 0,且变量 size_goal 的值为 14120。其中 size_goal 为单个 skb 可容纳的最大数据量,其在 tcp_send_mss 函数中被计算得出,下面为相关计算逻辑:
1 | static int tcp_send_mss(struct sock *sk, int *size_goal, int flags) |
1 | static unsigned int tcp_xmit_size_goal(struct sock *sk, u32 mss_now, // mss_now = 1412 |
1 | /* Bound MSS / TSO packet size with the half of the window */ |
注释已经详细解释了 size_goal 的计算逻辑,回到 line 1295@tcp.c,可知此时发送队列中没有 skb,所以此时需要申请新的 skb,且申请 skb 的 size 由 select_size(sk, sg, first_skb) 计算得出:
1 | static int select_size(const struct sock *sk, bool sg, bool first_skb) |
1 | /* Do not bother using a page frag for very small frames. |
经过验证,当前的 sk 是支持 GSO 的,所以此时会调用 linear_payload_sz(first_skb) 计算线性数据区的大小,因为此时是首个 skb,所以此处做了启发式的处理,如注释所阐述:
Do not bother using a page frag for very small frames.
But use this heuristic only for the first skb in write queue.
随即调用 SKB_WITH_OVERHEAD(2048 - MAX_TCP_HEADER) 进行计算,其中 SKB_WITH_OVERHEAD 的定义为:
1 |
即对于首个 skb,调用 sk_stream_alloc_skb 方法时的 size 值为 SKB_WITH_OVERHEAD(2048 - 320) = SKB_WITH_OVERHEAD(1728) = 1728 - 320 = 1408,继续跟踪 sk_stream_alloc_skb 的代码:
1 | struct sk_buff *sk_stream_alloc_skb(struct sock *sk, int size, gfp_t gfp, |
不难发现是调用 alloc_skb_fclone 函数进行的 skb 的实际申请,且传入至 alloc_skb_fclone 方法的 size 为 size + sk->sk_prot->max_header 即 1408 + 320 = 1728,继续跟踪至 __alloc_skb 函数:
1 | /** |
不难发现对于 first skb,计算出的 skb->truesize 为 2304,注意这 2304 字节中是含有 1408 的线性数据区的,这也应证了我们在探测点 line 1330@tcp.c 观察到的数据:
1 | time: 1669732990, line 1330@tcp.c, sk->sk_wmem_queued: 0, sk->sk_sndbuf: 87040, skb address: ffff8a21b0064200, skb->len: 0, skb->data_len: 0, skb->truesize: 2304 |
接着在 /* Where to copy to? */ 的提示下判断本次拷贝至线性数据区还是非线性数据区:
1 | /** |
1 | static inline bool skb_is_nonlinear(const struct sk_buff *skb) |
关于 skb 的 len 和 data_len 字段的解释如下:
len is the full length of the data in the packet, while data_len is the length of the portion of the packet stored in separate fragments. The data_len field is 0 unless scatter/gather I/O is being used.
因为当前申请的 skb 中含有线性数据区,所以此时会拷贝数据至线性数据区,根据当前的 skb 信息:skb->len: 0, skb->data_len: 0, skb->end: 1728, skb->tail: 320, skb->reserved_tailroom: 0 可计算出 skb_availroom 返回的值为 1728 - 320 - 0 = 1408 即线性数据区的大小。即对于应用层首次写入的 8192 字节的数据,会先将这 8192 字节中的前 1408 字节复制至首个 skb 的线性数据区中,接着会调用 skb_entail(sk, skb); 将该 skb 入队,此时会将 skb->truesize 累加至 sk->sk_wmem_queued:
1 | static void skb_entail(struct sock *sk, struct sk_buff *skb) |
注意因为含有线性数据区的 skb 的 truesize 在分配 skb 时包含了线性数据区的空间,即此处入队时累加至 sk->sk_wmem_queued 的 skb->truesize 值为分配 skb 时的值,即 2304,所以在复制至线性数据区的过程中无需再累加复制的字节数至 sk->sk_wmem_queued。这也可以通过线性数据区数据拷贝相关函数来证明:
1 | static inline int skb_add_data_nocache(struct sock *sk, struct sk_buff *skb, |
1 | /** |
1 | static inline int skb_do_copy_data_nocache(struct sock *sk, struct sk_buff *skb, |
即仅将需要拷贝至 skb 线性数据区的数据量 copy 累加至 skb->tail 和 skb->end,而不会再累加至 sk->sk_wmem_queued。接着我们在 line 1407@tcp.c 观察到应用层传入的 msg 还剩 6784 字节,因为 8192 字节拷贝了 1408 字节,所以对于该 msg 还剩 6784 字节需要拷贝:
1 | time: 1669732990, line 1407@tcp.c, sk->sk_wmem_queued: 2304, sk->sk_sndbuf: 87040, skb address: ffff8a21b0064200, skb->len: 1408, skb->data_len: 0, skb->truesize: 2304, msg_left: 6784 |
接着在如下的判断逻辑中:
1 | if (!msg_data_left(msg)) { // 如果 msg 里面没有需要拷贝的数据了,则 goto out |
因为此时 msg 还有数据,所以不会执行 goto out;,而是在 skb->len < max -> 1408 < 14120 的判断中会返回 true 从而执行 continue;,即进入 while 循环继续进行数据拷贝。接着又到了 line 1295@tcp.c,此时 line 1294@tcp.c 调用 skb = tcp_write_queue_tail(sk); 获取了发送队列尾部的 skb:
1 | time: 1669732990, line 1295@tcp.c, sk->sk_write_queue->qlen: 1, sk->sk_write_queue->tail address: ffff8a21b0064200, size_goal: 14120 |
此时可观察到发送队列长度为 1,即之前申请的首个 skb,且已经拷贝了 1408 字节的数据至该 skb。接口在 line 1298@tcp.c 执行 copy = max - skb->len; 计算本次可以拷贝的数据上限,可知此时 copy = 14120 - 1408 = 12712,随即在 /* Where to copy to? */ 的判断中会对当前的 skb 空间进行判断,此时的 skb 信息为:
1 | skb->len: 1408, skb->data_len: 0, skb->end: 1728, skb->tail: 1728, skb->reserved_tailroom: 0 |
根据此数据计算得出 skb_availroom 的返回值为 0,故只能拷贝至非线性数据区,这部分的代码为:
1 | static inline int skb_copy_to_page_nocache(struct sock *sk, struct iov_iter *from, |
line 1370@tcp.c 可以观察到拷贝至非线性数据区前的 skb 信息,便于与拷贝数据后的 line 1407@tcp.c 探测点进行数据对比。拷贝完后到达 line 1407@tcp.c 时的探测数据如下:
1 | time: 1669732990, line 1407@tcp.c, sk->sk_wmem_queued: 9088, sk->sk_sndbuf: 87040, skb address: ffff8a21b0064200, skb->len: 8192, skb->data_len: 6784, skb->truesize: 9088, msg_left: 0 |
可以看出此时 skb->len: 8192,即应用层传入的 8192 字节的数据全部拷贝至了该 skb,其中线性数据区含有 1408 字节的数据,非线性数据区含有 6784 字节的数据,即 skb->data_len 的值:6784。同时 msg_left 为 0 也可以证明 msg 的数据已经全部被拷贝。接着在 line 1408@tcp.c 中判断出 msg 已经没有剩余的数据,将执行 goto out; 跳转至 out。
1 | if (!msg_data_left(msg)) { // 如果 msg 里面没有需要拷贝的数据了,则 goto out |
1 | out: |
因为 copied 不为 0,此时会调用 tcp_push 函数,跟随该调用链路,可知将调用至 tcp_write_xmit:
1 | /* This routine writes packets to the network. It advances the |
该函数虽然细节较多,但是总体处理逻辑可以简化为不停判断当前队首 skb 是否满足发送的条件,如果满足,则进行发送并将其从发送队列移动至重传队列。对于首个 skb,可知在执行至 line 2415@tcp_output.c 时的相关信息如下:
1 | time: 1669732990, line 2415@tcp_output.c, sk->sk_write_queue->qlen: 1, sk->sk_write_queue->tail address: ffff8a21b0064200, tail_skb->len: 8192, tail_skb->data_len: 6784,tail_skb->truesize: 9088, mss_now: 1412, limit: 7060 |
其中的 limit 值由 tcp_mss_split_point 函数计算得出,而在调用 tcp_mss_split_point 函数前调用 tcp_cwnd_test 函数计算了拥塞窗口的配额 cwnd_quota:
1 | /* Can at least one segment of SKB be sent right now, according to the |
计算出了拥塞窗口配额将作为 max_segs 传入 tcp_mss_split_point 函数:
1 | /* Returns the portion of skb which can be sent right away */ |
在该函数中,计算出分割点为 7060,即我们准备发送包含 5 个 Segment 的包,每个 Segment 为 1412 字节,5 个 Segment 则为 7060 字节。回到之前的主流程,因为 skb->len > limit 结果为 true,将调用 tso_fragment 函数使用计算的分割点将 skb 拆分为多个 skb:
1 | /* Trim TSO SKB to LEN bytes, put the remaining data into a new packet |
根据前文的分析,我们知道首个 skb 中含有 1408 的线性数据区,并非全部由页面数据组成,所以在 tso_fragment 函数中会执行如下逻辑:
1 | /* All of a TSO frame must be composed of paged data. */ |
即进行 TCP 分段:
1 | /* Function to create two new TCP segments. Shrinks the given segment |
对于传入的 skb,将拆分为两个 skb,其中一个 skb 长度为 7060,另一个 skb 数据长度为 8192 - 7060 = 1132,以上代码中的 buff 即是拆分出的第二个 skb,注意因为产生了新的 skb, 则 sk->sk_wmem_queued 也将新 skb buff 的 head 这部分内存占用进行了累加,此时的 buff->truesize 为 1280,该值的计算逻辑可参考之前提到的 __alloc_skb 函数,在该函数实现的注释中解释了 1280 这个数值的计算过程。随即进行一些处理后将 buff 链接至 skb 后。
拆分完成后将返回至 tcp_write_xmit 函数中对队首的 skb 进行发送,注意此时队首的 skb 长度已经只有 7060 了,此时在 line 1029@tcp_output.c 观察到的 skb 信息如下:
1 | time: 1669732990, line 1029@tcp_output.c, sk->sk_wmem_queued: 10368, sk->sk_sndbuf: 87040, skb address: ffff8a21b0064200, skb->len: 7060, skb->data_len: 5652, skb->truesize: 7956, clone_it: 1 |
相比之前的探测点,不难发现 sk->sk_wmem_queued 已经由 9088 增加至了 10368,其增加的 1280 即为 buff 的 head。同时可观察到拆分后的首个 skb 的信息。接着在 tcp_write_xmit 函数的 while 循环中对拆分出的第二个 skb 进行了发送。以上两个 skb 发送后,经过层层返回,将完成应用层的首次 write 调用,即写入了应用层的 8192 字节数据。接着应用层发起了第二次 write 调用,需要写入的数据大小依然为 8192,与首次写入类似,此时进入 tcp_sendmsg_locked 方法的 while 循环中,观察到的发送队列信息为:
1 | time: 1669732990, line 1295@tcp.c, sk->sk_write_queue->qlen: 0, sk->sk_write_queue->tail address: ffff8a210074a358, size_goal: 14120 |
即发送队列中已经没有 skb 了,此时的 tail 实际为 NULL,然后申请新的 skb,注意此次申请 skb 与首次 skb 申请的不同之处在于此时计算的 first_skb 变量为值为 false,因为之前的两个 skb 虽然不存在于发送队列了,但是被移动到了重传队列中,所以 first_skb = tcp_rtx_and_write_queues_empty(sk); 计算出的 first_skb 值为 false,以使该变量导致 linear_payload_sz 返回值为 0,即启发式处理仅针对首个 skb,所以本次的 skb 返回的需要申请的线性数据区大小为 0,我们也可从探测点 sk_stream_alloc_skb@tcp.c 的探测信息验证以上逻辑:
1 | time: 1669732990 sk_stream_alloc_skb@tcp.c, size: 0, force_schedule: 0 |
随即将该 skb 入队并将应用层传入的 8192 字节全部复制至非线性数据区:
1 | time: 1669732990, line 1330@tcp.c, sk->sk_wmem_queued: 10368, sk->sk_sndbuf: 87040, skb address: ffff8a21b0065600, skb->len: 0, skb->data_len: 0, skb->truesize: 1280 |
根据以上探测点的数据可以观察到 sk->sk_wmem_queued 分别增加了 1280 和 8192,分别是 skb 的 head 和应用层复制的字节数,之前亦有类似的分析,所以此处不再展示计算过程。紧接着尝试发送该 skb,在 tcp_write_xmit 的 while 循环中,计算出最新的 limit 为 5648,此处为什么是 5648 呢,因为拥塞窗口中只能容纳 4 个段了,此时的拥塞窗口的配额计算如下:
1 | /* Can at least one segment of SKB be sent right now, according to the |
即因为在途的包(TSO 分片后)的数量为 6 个,所以此时只能发送 4 个。回到之前的主流程,因为 skb->len > limit 那么调用 tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE, skb, limit, mss_now, gfp) 对该 skb 分片,注意该 skb 与首个 skb 的不同之处在于该 skb 的数据全部位于非线性数据区,即 skb->len 与 skb->data_len 值相等,均为 8192,于是将在 tso_fragment 函数中执行分段逻辑,此处将长度为 8192 的 skb 拆分为长度为 5648 和 2544 的两个 skb,因为生成了新的 skb,所以 sk->sk_wmem_queued 对新申请的 skb 的 head 进行了累加。接着对拆分出的首个 skb 进行了发送,即将长度为 5648 的 skb 进行了发送。随即准备发送长度为 2544 的 skb,但是在 line 2381@tcp_output.c 对应的 tcp_cwnd_test 函数的判断逻辑中,此时网络中的包(TSO 分片后)的数量为 ROUND_UP(7060/1412) + ROUND_UP(1132/1412) + ROUND_UP(5648/1412) = 10,即已经大于等于拥塞窗口允许的包的数量(tp->snd_cwnd = 10),所以这个 skb 就没有再发送了。如果仔细观察探测点的输出,不难发现长度为 2544 的 skb 的地址为 ffff8a21b0064800,结合后面的探测点,可以发现该 skb 一直处于发送队列的队首,即一直没被发送出去。其实分析到这里,已经分析出之前 WireShark 截图中 FIN/ACK 之后后端服务器发送至负载均衡的三个包了,如果仔细观察上面的截图,不难发现这三个包的 TCP Segment Length 分别为 7060、1132、5648,即与我们探测到的发送的 skb 的长度相匹配。如果继续分析下去,会发现发送队列中的 skb 都被填满至 size_goal 即 14120,直到 sk->sk_wmem_queued 的值大于等于 sk->sk_sndbuf,注意此处的判断是在当前 skb 已满的情况下执行的,此时对应的探测点数据为:
1 | time: 1669732990, line 1407@tcp.c, sk->sk_wmem_queued: 94296, sk->sk_sndbuf: 87040, skb address: ffff8a21b0065a00, skb->len: 14120, skb->data_len: 14120, skb->truesize: 15400, msg_left: 5672 |
即当前 skb 已满,且本次写入了 8192 - 5672 = 2520 字节,对应着 Sysdig 观察到的 res 等于 2520 的事件,随即将执行 goto wait_for_sndbuf; 跳转至 wait_for_sndbuf:
1 | while (msg_data_left(msg)) { |
在跳转后的逻辑中将执行 sk_stream_wait_memory:
1 | /** |
因为 Socket 为非阻塞的,所以会执行 goto do_eagain; 进行跳转,设置 err = -EAGAIN; 后执行 goto out; 将 err 返回。随着层层返回,将到达之前提到的 JVM 层的 convertReturnVal 方法,在该方法中,当错误码为 EAGAIN 时,将返回 IOS_UNAVAILABLE:
1 | else if (errno == EAGAIN) |
关于 IOS_UNAVAILABLE 的定义位于 nio.h:
1 |
即对应 IOStatus 类中的静态变量 UNAVAILABLE,源码位于 IOStatus.java:
1 | // Constants for reporting I/O status |
正如注释及源码所告知的,如果状态码为 UNAVAILABLE,则将在 IOStatus.normalize(n) 方法调用中转换为 0。即在之前分析的 socket.write 的底层调用中 SocketChannelImpl.java:
1 | public int write(ByteBuffer buf) throws IOException { |
调用 IOStatus.normalize(n) 将 UNAVAILABLE 转换为 0,即我们在 Tomcat 线程调用 socket.write 方法时接收到的 cnt 变量的值。以上即为首次调用 socket.write 至首次收到 cnt 为 0 的发送流程的主要执行路径。如果更加仔细地观察,不难发现重传场景下 FIN/ACK 之后的第四个包来自于 tcp_send_loss_probe 调用,此时传入的 push_one 变量值为 2,在 tcp_write_xmit 函数中会再触发一个段的传输,且该包在 WireShark 的截图中与之前的包是存在一定的时间间隔的,因为并非应用层 socket.write 显式触发,而是由 tcp_timer.c 中的 tcp_write_timer_handler 函数中的 ICSK_TIME_LOSS_PROBE 事件触发,后续的重传包则来自 tcp_write_xmit。
返回至应用层的 cnt 为 0 导致了 Tomcat 线程的等待。这一切不能写入的主要原因为我们未收到负载均衡的 RST 包。最后经过负载均衡侧的排查,定位原因为中间的虚拟交换机丢弃了后端服务器写回至负载均衡侧的响应数据包。与起初我猜测的防火墙有差异,但是原理类似,即该虚拟交换机会维护后端服务器与外界通讯的 TCP 连接,当外界发送 FIN 包尝试关闭 TCP 连接时,此虚拟交换器配置的时间窗口为 7 + 9 = 16 秒:
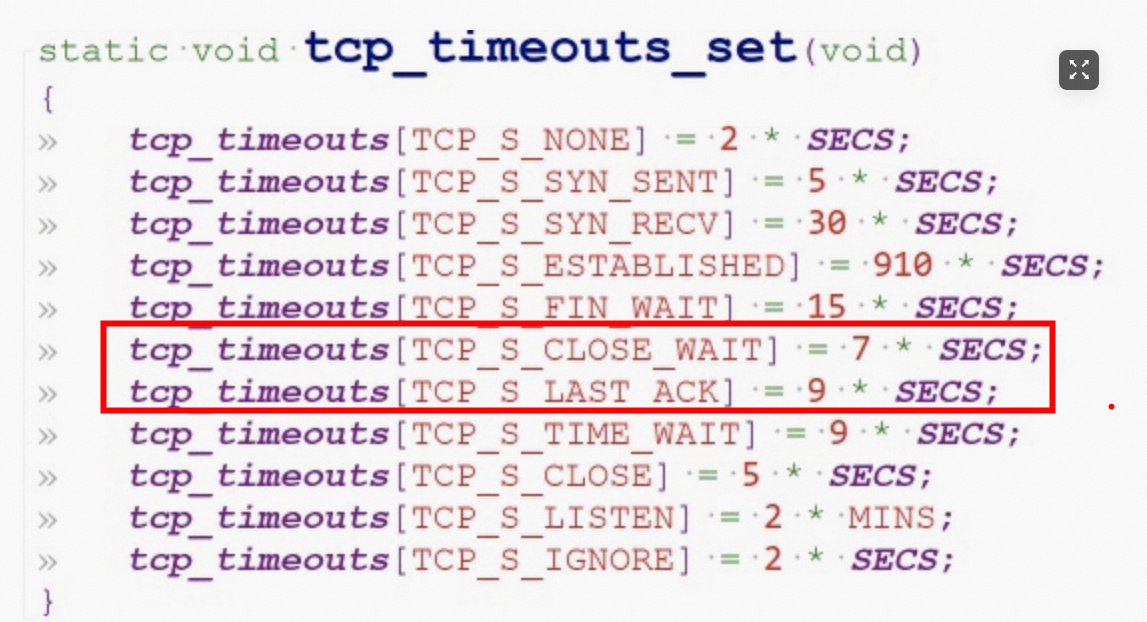
即自负载均衡的 FIN 包开始计时,若后端服务器在 16 秒后再响应数据包,此时虚拟交换机已经未维护当前 TCP 连接了,这部分包将被虚拟交换机丢弃,导致负载均衡无法收到这部分数据包,所以我们也无法接收到 RST 包。
下面总结下服务不能快速恢复的几个因素,正是因为多个因素共同叠加才导致了服务不能快速恢复这个问题:
- 自 FIN/ACK 包开始计时 16 秒后后端服务器响应的数据包被虚拟交换机 DROP 导致响应数据包根本未到达负载均衡侧,自然无法收到负载均衡侧的 RST 包,使连接不能及时终止
- 后端服务器未启用 gzip 压缩且存在响应数据约 90KiB 的接口,当前 gzip 在负载均衡侧实现,导致写入数据占用的内存超过 sndbuf 使 Tomcat 线程等待
- Tomcat 的默认配置中 TaskQueue 队列容量为
Integer.MAX_VALUE, 那么在后端服务器 Tomcat 线程池满至负载均衡摘除流量这段时间内的请求全部进入了 TaskQueue - Tomcat 8.5.59 中的实现导致本该 20s 写入超时的请求后续再尝试了两次,使单个请求写入占用线程的时间从 20s 增大到了 60s,使队列任务的消费时间是理想情况下的三倍
下面给出相关解决方案:
- 使用 tcpkill 快速 kill 掉堆积在 TaskQueue 中的处于 CLOSE_WAIT 状态的 TCP 连接,原理为发送 RST 包至后端服务器以使内核中该 Socket 的错误码为 EPIPE,此时应用层的 select 调用会收到
SocketEvent.OPEN_WRITE事件,随即执行countDown(attachment.getWriteLatch());使响应线程结束等待,随即进入 while 循环执行socket.write再次尝试写入,此时触发java.io.IOException: Broken pipe,然后被转换为ClientAbortException抛出,该线程退出前在processWorkerExit中重建新的线程继续快速处理队列中的任务以快速恢复服务(事故现场的临时解决方案) - 调整虚拟交换机配置,增大维护连接的超时时间(不推荐,超时时间不易控制)
- 调整负载均衡侧因后端服务器超时导致需要断开连接的实现方式为发送 RST 包至后端服务器而不是发送 FIN 包至后端服务器(推荐方案)
- 调整 Tomcat 配置,配置较低的 TaskQueue 容量以避免单个连接堆积与处理时长超过 16 秒,同时降低 Socket 写入超时时间以加快服务恢复(推荐方案)
- 升级 Tomcat 小版本,以规避
SocketTimeoutException抛出后的额外两次不必要的写入重试(推荐方案)
Remark
以上仅分析了一种典型的请求,即后端服务器不能在负载均衡侧配置的请求超时时间加虚拟交换机的连接维护时间整个时间范围内处理完请求的情况。实际上我们还观察到部分客户端请求库指定了超时时间时,如果未在指定的超时时间内收到响应,则此时客户端会发送 FIN 关闭与负载均衡间的 Socket 连接,此时会导致负载均衡侧同步发送 FIN 至后端服务器关闭负载均衡与后端服务器的连接,从此刻开始计时,若后端服务器未在 16 秒内写回响应且该响应数据所占内存超过发送缓冲区的容量,也会导致相同的问题。总之,在后端服务器收到 FIN 包后,若未能在 16 秒内写回响应数据且该响应数据所占内存超过发送缓冲区的容量,则会导致 Tomcat 线程等待 60 秒,当 200 个 Tomcat 线程全部处理等待状态时,新的请求将进入 Tomcat 的 TaskQueue,直到负载均衡判定该后端服务器完全不可用不再使新的流量进入,那么在流量摘除前的这部分请求几乎全部堆积至队列中,整个服务恢复的时间即取决于队列中堆积的请求数及这部分请求中有多少请求响应数据所占内存超过发送缓冲区的容量,而对于响应数据所占内存小于发送缓冲区容量的这部分请求,实际上不会导致该问题,因为 NIO 的实现机制使应用层的数据写入至 skb 队列后就返回了,不会使 Tomcat 线程等待。
事实上我们在不同的负载均衡实现上观察到了超时场景下不同的连接断开方式,目前我们使用的负载均衡在此场景下使用 FIN 包与后端服务器断开连接,而其他的负载均衡可以观察到部分实现是使用的 RST 包断开与后端服务器的连接。
通过查询相关文档,可以发现 NAT 之类的中间层设备也存在类似的机制,即在 FIN 包后存在一个时间窗口,那么可以推断如果服务器与负载均衡之间如果存在相关设备,也可能导致相关问题,可参考以下链接:
- 设计使用 NAT 网关的虚拟网络 - Azure Virtual Network NAT | Microsoft Learn
- TCP Keepalive Best Practices - detecting network drops and preventing idle socket timeout
- Lessons from AWS NLB Timeouts. Jonathan Lynch, Alan Ning | by Alan Ning | Tenable TechBlog | Medium
在排查过程中还排除了 TCP 内存压力等其他的可能的一些情况,如观察到的 TCP 全连接队列溢出的问题,但与核心原因关系不大,所以文中并未体现。
References
Key Metrics for Monitoring Tomcat | Datadog
Apache Tomcat 8 Configuration Reference (8.5.83) - The HTTP Connector
Apache Tomcat 8 Configuration Reference (8.5.84) - The Executor (thread pool)
60319 – Executor limits reported via JMX can be inconsistent
How to find the socket buffer size of linux - Stack Overflow
How SKBs work
How SKB socket accounting works
How SKB data work
skbuff.pdf
17.10. The Socket Buffers
How the Linux TCP output engine works
TCP/IP - What are FIN_WAIT_1 and FIN_WAIT_2 TCP protocol states? | HPE Support Center
4.7. The Mysteries of Connection Close - HTTP: The Definitive Guide Book
Connection State As Known by TCP
Properly terminating HTTP connection from client’s side - Stack Overflow
Systems Resiliency: Simple Tomcat Backpressure | by Will Tomlin | Expedia Group Technology | Medium
who first sets tcp FIN flag in client-server connection - Stack Overflow
What is the meaning of the TSV and TSER fields in an Ethereal dump? - Stack Overflow
3.5. Closing a Connection - RFC 793: Transmission Control Protocol
Why the Sequence number in an ACK packet is incremented? - Server Fault
What is the difference between sock->sk_wmem_alloc and sock->sk_wmem_queued - Unix & Linux Stack Exchange
What is tcp_autocorking (tcp automatic corking) - Stack Overflow
write to TCP socket keeps returning EAGAIN - Stack Overflow